

At least 50 persons have claimed to have deciphered the Voynich Manuscript. A simple test I have developped helps to check whether a solution is correct.
Is the text in Voynich Manuscript written in an old Georgian dialect with Romanian influence? Or is it encrypted in a substitution cipher with nulls and transposition elements?
Honestly, I don’t know. Virtually all Voynich Manuscript experts consider the mystery of the text in the manuscript still unsolved (or assume that there is no solution at all). Nevertheless, there are at least 50 persons who have published solutions of the Voynich Manuscript mystery. None of these solutions has ever been accepted by the research community. In most cases there is only one person being convinced of a certain solution – the person who developped it.
To check if an alleged solution makes sense I have developped a simple test. I know that this test is far from perfect and that a positive result is no guarantee for a solution candidate to be correct, but it’s at least an important indicator.
How the test works
Look at the following text line:
century, many aspects of Italian culture and society remained largely Medieval
It is immediately clear that these words make sense. In fact, this line is taken from a Wikipedia article:
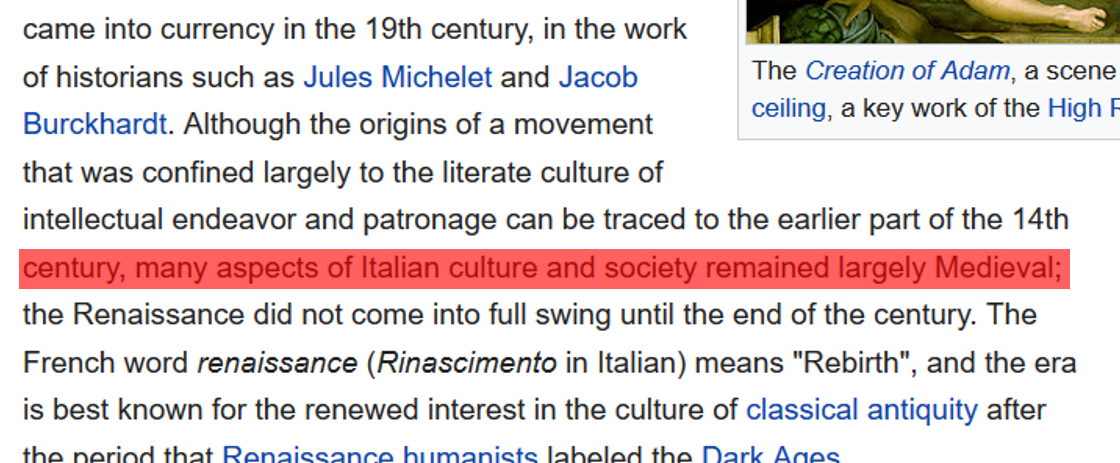
Next, look at the following line:
century Renaissance renaissance interest labled art and in lead
This time it’s pretty clear that these words don’t make sense. It’s because they were taken from different lines of the text:

The same thing can be done with the Voynich Manuscript. For instance, the following text represents a line (with the first word omitted) from page 58v of the manuscript (example A):
![]()
The location of this line on the page is indicated here:

The following line is compiled from words on page 66r of the manuscript (example B):
![]()
This time the words were taken from different lines:

It goes without saying that somebody who can read the text in the Voynich Manuscript should be able to tell that example A represents original Voynichese, while example B is nonsense.
The test
In the following, six lines consisting of original Voynich Manuscript words are listed (there might be more to come). Some lines were directly taken from the original text, others are sequences of words from different lines. If you think you have diciphered the text in the Voynich Manuscript you should be able to tell which of these lines are Voynichese and which are nonsense. Of course, I will keep the solutions confidential. If you think your Voynich Manuscript solution is correct and you can distinguish correct lines from incorrect ones, feel free to send me a mail.
Challenge 1
![]()
Challenge 2

Challenge 3
![]()
Challenge 4
![]()
Challenge 5
![]()
Challenge 6
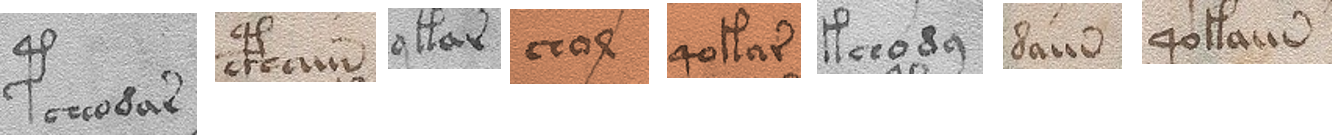
Is it possible to cheat?
Of course, there are ways to cheat in this test. For instance, one can transcribe the words of a line and search for them in a transcribed version of the Voynich Manuscript. The safest way to prevent this is to make sure that the person tested has no access to a transcription during the test. In addition, I hope that somebody who claims to have solved the Voynich Manuscript knows that he cheats himself if he cheats in this test.
Follow @KlausSchmeh
Further reading: Voynich manuscript: 898 official replicas and one unofficial one
Linkedin: https://www.linkedin.com/groups/13501820
Facebook: https://www.facebook.com/groups/763282653806483/

Kommentare (30)