

In a Kansas library an unknown person has written an encrypted message into a book. Can a reader solve this “book cipher”, which is probably not a book cipher?
Blog reader and Zodiac Killer expert David Oranchak …

Source: Schmeh
… has made me aware of an interesting crypto mystery. He saw it on Twitter …

Source: Twitter
… and posted it in the /r/codes group of Reddit. The Tweet was sent by a Kate Ray, who works for the Lawrence Public Library in Lawrence, Kansas. Kate wrote: “Unless you’re the Zodiac Killer, confessing your crimes and revealing your identity, please do not use library books to practice your secret codes.” Kate’s tweet refers to the following cryptogram a reader left behind in one of the library’s books (Assasin’s Apprentice by Robbin Hobb):

Source: Twitter
Dave has published the following transcription on Reddit:
YMBFPTYSYSNADSBYAACPTM YSNEMTMOIYJGTEBYNIAJ APSNDETMYLGAIDISYMI HFBYTFAAWOTYCMCHNEFTY IHSAWOYYHNEAWOWIWLTDI HAJBSASTFYTMMFDOETTD ITWYGMTIPDTTOFYANRSITL OACYANWYAJAHCTDSIHND ONIPEICNCOACOHMOOOT YPMDISWTOKIEYWOPRA AOTWFFFYOTYOMIHLYD WICSTOTIHHNCFBYHNLAO WALYCWOWTDSOLIOMWWW YNTLTYMYFYLNAWNMWSSI NDIDCWGOOBOYAYOFW GYKODLIAALACNSUFMSIAT OJBAHTYIANAWJSWDET OMYHABEODIASMGWIHDT TOTYHNDTIAPASYOAYDTS WBAAFYFNSMTMOTOHYA NSYJDWMABTDEKMMSA IHOMLTPYANWADNWTSWIS AIHNGTSTBFANTDWL
Here’s a frequency analysis made with CrypTool 2:
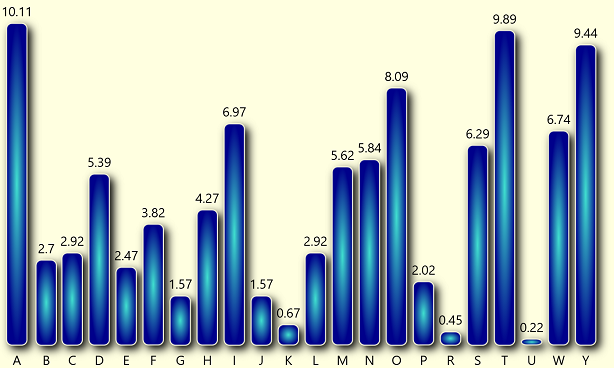
Source: Schmeh
This frequency distribution is consistent with a letter substitution (MASC) of an English plaintext. The same is true for the Index of Coincidence of the cryptogram, which is 6.3 percent. However, CrypTool 2, as well as online cryptogram solvers, such as Quipqiup or Rumkin.com, don’t render a result.
In a later tweet, Kate provided two more parts of the message (the cryptogram is spread to three pages, the second of which contains only one line):
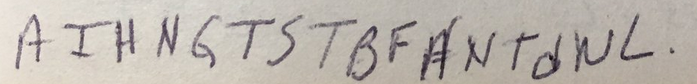

Source: Twitter
Here’s a transcription of the third page (i.e., the second full page) provided by Reddit user Thruster17:
IAAYYAARYNTTMIFLYTIA BYWYEWGOTAYNTTMWITA COSSOCAYSLIYATMTTOTT NAAMDOTWYNSOETBRNBAH TMAYSIDKINADRHBOFTW TTFBWSYJSBYKIWBMATO GTDALAYANIATADWCBYD DLOAHWIAFHWSTAYSTF OHSELTODTNOAMaHMA HWCUALFMTFYM.YNWTGTO G.AHTCHASOD.ATRISWNB. WISIAAOHB,BYCSTSIPYAA FITIYWSTASIABBaagi WSYCIATOYSIAWyd,BHS AIIMYMMFUIOIYRYCH CLEFAOWNHOTSADIHIW YCTTACBIWLFYTTiiM,L PIDOE,GSSIiMaTCIDLS DMSFHATHTLTIFTNWIA TOYLMJOMATLOIMFJMW YTOOMdYLDBLPCEAT
Considering that this message is contained in a book, it seems plausible that a book cipher was used. This would mean that the letters in the cryptogram point to letters, words or phrases in the book. However, I don’t see an obvious way how these letter sequences can be interpreted as page numbers and pointers to certain positions. In addition, the letter frequencies and the Index of Coincidence are typical for a MASC, not for a book cipher.
Can a reader find out more about this strange cryptogram?
Follow @KlausSchmeh
Further reading: The Top 50 unsolved encrypted messages: 10. James Hampton’s notebook
Linkedin: https://www.linkedin.com/groups/13501820
Facebook: https://www.facebook.com/groups/763282653806483/

Kommentare (22)