

Machine Learning — ein tolles Buzzword das man ständig in allen möglichen Zusammenhängen hört. Amazon macht euch Kaufvorschläge? Machine Learning sei Dank. Ein Computer schlägt den Go-Weltmeister. Machine Learning sei Dank. Euer Smartphone versteht euch, wenn ihr mit ihm redet? Machine Learning sei Dank.
Kinder vs. Computer
Aber was bedeutet Machine Learning. Wie können Maschinen dazu in der Lage sein zu “lernen”? Was bedeutet “Lernen” eigentlich? Wikipedia sagt: “Unter Lernen versteht man den absichtlichen oder beiläufigen Erwerb von geistigen, körperlichen, sozialen Kenntnissen, Fähigkeiten und Fertigkeiten.” Stellen wir uns folgendes Beispiel vor: Eine Mutter läuft mit ihrem Kleinkind durch die Stadt. Eine Katze läuft ihnen über den Weg. Das Kind zeigt auf die Katze und freut sich. Die Mutter bringt ihm bei “Das ist eine Katze”. Sie laufen weiter. Ein Hund läuft ihnen über den Weg. Das Kind deutet auf den Hund und sagt “Katze”. Die Mutter sagt “Nein, das ist keine Katze”. Anhand solcher Positiv- und Negativbeispiele lernen Kinder die Welt um sich herum kennen und einzuordnen. Und genau anhand solcher Positiv- und Negativbeispiele kann das auch eine Maschine. In dem Fall spricht man von Überwachtem Lernen.
Die Welt in Schubladen einteilen
Eine typische Anwendung für Machine Learning sind Klassifizierungsprobleme. Menschen stecken ja gerne alles in Schubladen und haben das auch dem Computer beigebracht. Dabei gibt es zwei unterschiedliche Herangehensweisen: Entweder kennt man die Schubladen schon vorher (alle Katzen in die Katzenschublade, alle Hunde in die Hundeschublade usw) oder man muss die Schubladen erst noch herausfinden.
Nehmen wir mal an, wir kennen die Schubladen schon, dann könnte man den Computer mit Regeln füttern, nach denen er zum Beispiel Bilder in diese Schubladen sortiert: “Wenn es Fell, einen Schwanz, dreieckige, aufrechte Ohren und Schnurrhaare hat, ist es eine Katze”. Machine Learning benötigt aber eben genau diese Regeln nicht. Wir müssen die Regeln also nicht formulieren können. Stattdessen füttern wir den Computer mit Positiv- und Negativbeispielen. Ein Beispiel besteht aus einer Menge an Eigenschaften, zum Beispiel Schwanz, Fell, Augen, Augenfarbe, Größe, usw. und der Einordnung ob es eine Katze ist oder nicht. Wenn man dem Computer genügend Positiv- und Negativbeispiele gegeben hat, kann er danach selbst entscheiden, ob auf dem Bild eine Katze zu sehen ist oder nicht.
Welcher Typ Mountainbiker bist du?

Bild von https://mpora.de/articles/welcher-typ-mountainbiker-bist-du.html
Habt ihr schon mal einen dieser Tests in einer Zeitschrift gemacht, bei denen man durch ein Diagramm geführt wird indem man Fragen beantwortet? Eine weit verbreitete Machine Learning Methode funktioniert auf eine ähnliche Weise. Man spricht hier von Entscheidungsbäumen. Die Fragen in den Zeitschriften erscheinen oft logisch und man weiß meist schon vorher, in welche Schublade man am Ende gesteckt wird. Es sind diese “formulierten Regeln” nach denen wir Menschen vorgehen. Die Fragen, die in von Computern erstellten (gelernten) Entscheidungsbäumen gestellt werden, erscheinen für uns Menschen nicht unbedingt so logisch. Meist wird auch nicht ein einzelner Entscheidungsbaum erstellt, sondern viele. So als würdet ihr mehrere Tests zur gleichen Frage machen. Am Ende entscheidet man dann nach der Mehrheit.
Ein Raum voller Katzen und Nicht-Katzen
(nein, hier geht es nicht um Schrödinger)
Eine andere Methode sind Supportvektor-Maschinen. Wie Turingmaschinen, sind sie keine echten mechanischen Maschinen, sondern ein mathematisches Verfahren. Stellen wir uns vor, wir haben 1000 Positiv- und Negativbeispiele (“Katzen” vs “keine Katzen”), die wieder jeweils bestimmte Eigenschaften haben (Schwanz, Fells usw). Wir können uns ein einzelnes Beispiel als einen Punkt vorstellen, der durch seine Eigenschaften einen bestimmten Platz in einem Raum einnimmt. Wenn wir alle Beispiele als Punkte in diesem Raum betrachten, dann können wir eine Wand in den Raum einziehen, die die Katzen, von den Nicht-Katzen trennt. Ok, ganz so einfach ist es oft nicht. Oft sind die Punkte so im Raum verteilt, dass sie sich nicht sauber durch eine “Wand” trennen lassen. Man sagt, sie sind nicht “linear trennbar”. Man verwendet dann den sogenannten “Kernel-Trick”: Man projiziert den Raum in einen höherdimensionalen Raum, in dem die Punkte linear trennbar werden. Stellt euch ein Blatt Papier vor auf das rote und grüne Punkte gezeichnet sind, die sich nicht sauber mit einem geraden Schnitt voneinander trennen lassen. Wenn ihr das Papier aber richtig faltet, dann wird das aber auf einmal möglich.
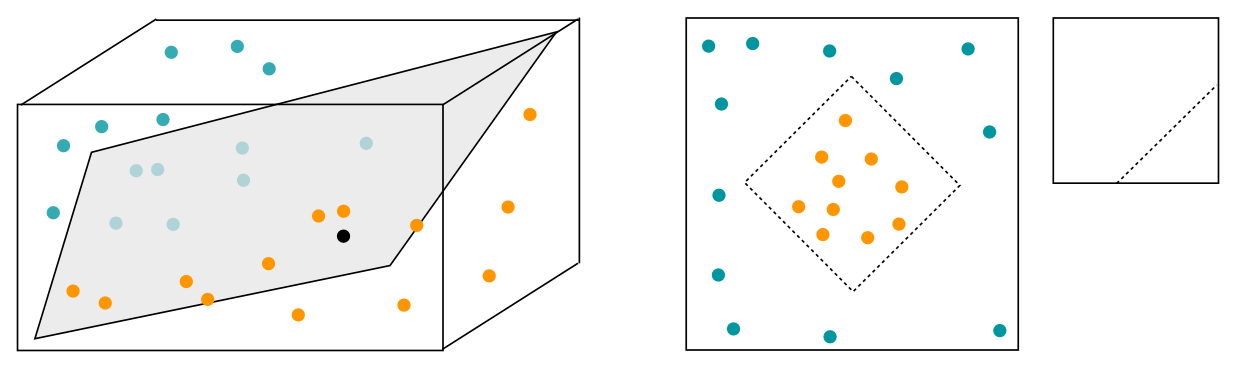
Wenn wir dem Computer jetzt ein unbekanntes Bild zeigen, dann macht er daraus wieder einen Punkt in dem Raum mit der Wand. Je nach dem auf welcher Seite der Wand der Punkt liegt, wissen wir, ob es eine Katze ist, oder nicht.

Kommentare (9)