Die Welt des Menschen besteht aus Sprache. Wir können an Hand von Worten nicht nur unsere Bedürfnisse äußern, Kritik üben und Wunschzettel für den Weihnachtsmann ansprechend aufsetzen, Sprache erlaubt es uns auch, unsere Kultur an zukünftige Generationen weiter zu vermitteln. Dabei ist jedes Wort, das wir irgendwo hin kritzeln, ein klitzekleiner eingefrorener Ausschnitt aus unserer momentanen Welt. Untersucht eines Tages jemand die Worte, die wir heute benutzen, kann er viel über uns lernen. Aber viel mehr noch kann man durch die Veränderungen in unserer Sprache über die Veränderungen in der menschlichen Entwicklung erfahren.
 Ein Team aus Harvard nutzte jetzt einen Großteil des Archivs von Google Books – das sind über 5 Millionen eingescannte Bücher, oder 4 % aller jemals gedruckten Werke – um die Rolle von Sprache in unserer Gesellschaft über die Zeit zu verfolgen. Sie werteten 500 Milliarden Wörter aus sieben Weltsprachen aus (37 Milliarden davon aus deutschen Büchern). Eine riesige Datenmenge. Zum Vergleich: Das menschliche Genom besteht aus ca. 3 Milliarden “Buchstaben”. In ihrer Publikation erläutern die Autoren diesen Datenwust noch weiter: Wenn man in einer geraden Linie schreiben würde, könnte man mit dieser Anzahl an Worten die Strecke von der Erde zum Mond zehnmal überbrücken. Versucht man das aber als sterblicher Mensch zu lesen, kommt man nicht weit – allein die Einträge aus dem Jahr 2000 würden bei zügigem Lesen (und ohne zu essen oder zu schlafen) 80 Jahre dauern.
Ein Team aus Harvard nutzte jetzt einen Großteil des Archivs von Google Books – das sind über 5 Millionen eingescannte Bücher, oder 4 % aller jemals gedruckten Werke – um die Rolle von Sprache in unserer Gesellschaft über die Zeit zu verfolgen. Sie werteten 500 Milliarden Wörter aus sieben Weltsprachen aus (37 Milliarden davon aus deutschen Büchern). Eine riesige Datenmenge. Zum Vergleich: Das menschliche Genom besteht aus ca. 3 Milliarden “Buchstaben”. In ihrer Publikation erläutern die Autoren diesen Datenwust noch weiter: Wenn man in einer geraden Linie schreiben würde, könnte man mit dieser Anzahl an Worten die Strecke von der Erde zum Mond zehnmal überbrücken. Versucht man das aber als sterblicher Mensch zu lesen, kommt man nicht weit – allein die Einträge aus dem Jahr 2000 würden bei zügigem Lesen (und ohne zu essen oder zu schlafen) 80 Jahre dauern.
Die Auswertung wurde selbstverständlich von Computern übernommen und ist bei Google mittlerweile über den sogenannten Ngram Viewer 1 verfügbar. Er lädt ein zum Herumspielen. Jürgen von Geograffitico hat dies auch schon mal getan, um zu sehen wie viel in den letzten paar Jahrhunderten eigentlich über Gott und die Welt geschrieben wurde.
Die Analysen, die nun online in Science veröffentlicht wurden, sind spannend. Im englischsprachigen Raum hat sich der Wortschatz zwischen 1900 und 2000 von ca. 500 000 Wörtern auf über 1 Million fast verdoppelt. Im Deutschen ist die “Frau” zunehmend stärker in Büchern aufgetaucht. Zwischen 1936 und 1944 verschwand der Künstler Marc Chagall aus den meisten deutschen Büchern, genau wie Pablo Picasso, während sie im englischen Sprachraum gleichmäßig weiter anstiegen. In der Kategorie “Berühmte, häufig erwähnte Persönlichkeiten” war lange Zeit “Sigmund Freud” deutlich in Führung, seit ca. 1995 fiel er aber stark ab und läuft Gefahr von “Charles Darwin” und “Albert Einstein” überholt zu werden.
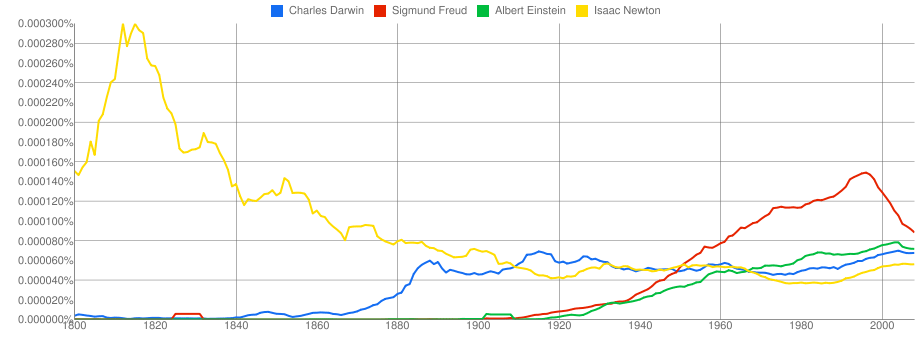
Ngram: Häufigkeit, mit der vier (völlig zufällig ausgewählte) Persönlichkeiten in der untersuchten Literatur auftauchen. (Zum Vergrößern bitte auf das Bild klicken.)
Das nächste Ziel der Wissenschaftler ist der Kontext, in dem Worte, Namen und auch Zahlen auftauchen. Sie wollen die unmittelbaren Umgebung von Worten genauer untersuchen. Interessant fänden sie zum Beispiel ob der Kontext, in dem “Gott” erwähnt wird, sich über die letzten Jahrhunderte änderte.
Die Evolution der Grammatik
Ein spezielles Augenmerk wurde auf Verben gerichtet. Im Englischen gibt es ja irreguläre und reguläre Verben. Irreguläre sind die, die man in der Schule auswendig lernen musste, aber die doch sofort wieder aus den Köpfen verschwanden (to go, went, gone); nur durch die vielen regulären Verben machte der Englischunterricht glücklicherweise doch noch Spaß (to enjoy, enjoyed, enjoyed). Dies wurde durch die Studie bestätigt. Einfach zu merkende Verben trotzten den schweren Zeiten besser als komplizierte. Oder wie die Autoren es schön formulieren:
Eines meiner Lieblingsworte (im Englischen), mit dem ich mich immer rumärgern musste weil ich konstant den Eindruck hatte, es falsch zu benutzen, bekam eine Sonderstellung in der Studie. “to sneak” heißt schleichen, oder auch stibitzen. Interessanterweise wechselte in den USA die Popularität der Vergangenheitsform von Jahr zu Jahr. Während in manchen Jahren die Vergangenheitsform “sneaked” favorisiert wurde, ist es in einem anderen “snuck”. Ich bin erleichtert zu lernen, dass nicht nur ich die beiden jeweils nach Stimmung und Wetterbedingungen (oder sonst irgendwelchen willkürlichen Begründungen) auswählte. Es ist die gesamte US-amerikanische Literatur – oder genauer gesagt: 4 % davon.
Kommentare (10)