

Was haben ausgerechnet Mäuse, Bäume und Viren mit Bioinformatik zu tun? Sollte ich nicht eher von DNA, Menschen, Krebs und Algorithmen reden? Gucken wir uns die Begriffe doch mal genauer an:
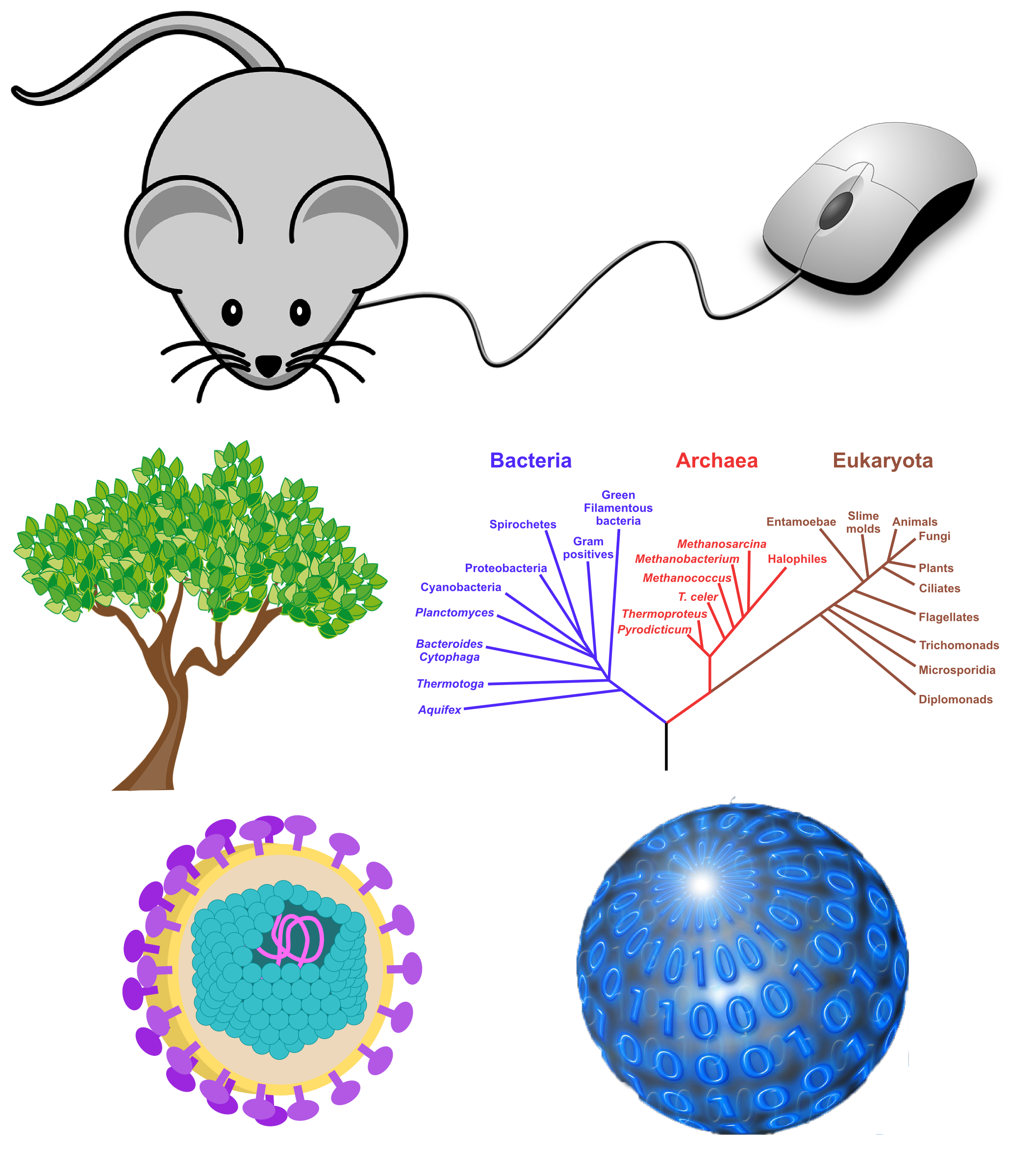 Die Maus: (Mus musculus) weltweit verbreitetes kleines Nagetier.
Die Maus: (Mus musculus) weltweit verbreitetes kleines Nagetier.
Die Maus: Standardeingabegerät für den Computer.
Der Baum: verholzte Pflanze, bestehend aus Wurzel, Stamm und Krone.
Der Baum: spezieller Graph, der zusammenhängend ist und keine geschlossenen Pfade enthält.
Das Virus: infektiöser Partikel, der sich nur innerhalb einer Wirtszelle vermehren kann.
Das Virus: sich selbst verbreitendes Computerprogramm, welches sich in andere Computerprogramme einschleust und reproduziert.
Habt ihr es erkannt? Maus, Baum und Virus sind Begriffe, die sowohl in der Biologie als auch in der Informatik eine Bedeutung haben. Sie stehen für mich stellvertretend für die Verbindung zweier Welten.
Die Verbindung zweier Welten
Warum heißt die Computermaus eigentlich Maus? Ursprünglich wurden Mäuse noch per Kabel mit dem Computer verbunden. Die Form der Computermaus in Verbindung mit dem Kabel erinnerten einfach stark an das kleine Nagetier. Warum nennen die Informatiker eine Gruppe von Graphen Bäume? Zu diesen speziellen Graphen zählen zum Beispiel Stammbäume — das sind natürlich keine echten Bäume, sondern eher eine Darstellung der evolutionären Abstammungsgeschichte. Aber wie bei einem Baum, gibt es auch in einem Stammbaum eine Wurzel und Verzweigungen bishin zu den Blättern: das sind wir selbst. Und warum spricht man von einem Computervirus? Viren dienen nur ihrer eigenen Vermehrung in einer fremden Wirtszelle und können dabei (versehentlich) Schaden anrichten. Das gleiche gilt auch für einen Computervirus. Nur dass der Schaden dabei wohl eher beabsichtigt ist.
Biologie in Informatik umsetzen, durch Informatik die Biologie vorantreiben, uns aus der Biologie Ideen für die Informatik ziehen — genau diese Denkweisen sind es, die man als Bioinformatiker erlernen muss. Biologie und Informatik haben viel mehr gemeinsam, als einem im ersten Moment bewusst ist. Neben Maus, Baum und Virus, gibt es viele Ideen und Konzepte, die sowohl in der Informatik als auch der Biologie eine Bedeutung haben. Lasst mich euch zwei kleine Beispiele geben:
Unser Gehirn im Computer
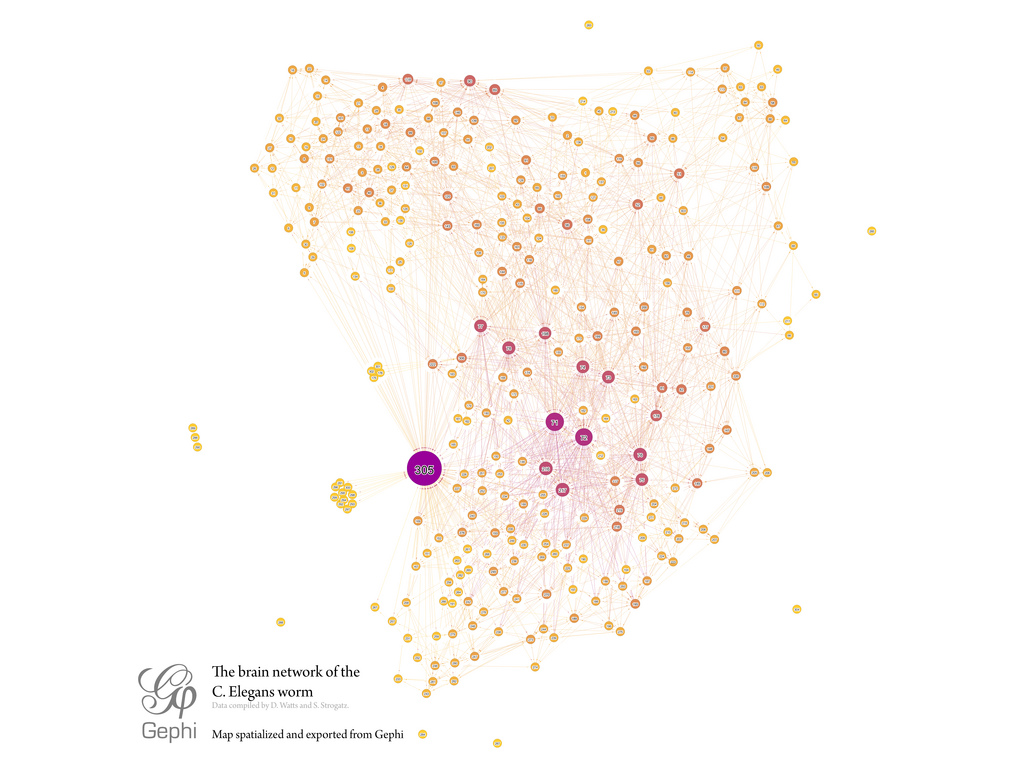
Das neuronale Netzwerk des Fadenwurms.
(Von Mentatseb, CC BY-SA 3.0)
Die Nervenzellen (Neuronen) in unserem Gehirn sind über Synapsen miteinander verknüpft und bilden ein Netzwerk. So können sich die Neuronen miteinander austauschen und Informationen als Signale weiterleiten. Eine Nervenzellen hat üblicherweise mehrere eingehende Nervenzellen und einen Ausgang. Kriegt die Nervenzelle genügend Eingangssignal, leitet sie ein Ausgangssignal weiter. Solche neuronalen Netze ermöglichen es, komplexe Muster zu lernen. Und zwar nicht nur in unserem Gehirn, sondern auch im Computer. Solche künstlichen neuronalen Netze werden zum Beispiel für maschinelle Gesichtserkennung verwendet. Genau wie unser Gehirn müssen auch die künstlichen Netze trainiert werden. Dann können sie aber Großes leisten. AlphaGo, das erste Computerprogramm, dass es geschafft einen Menschen im Go spielen zu schlagen, beruht auf einem künstlichen neuronalen Netz.
Omnia casu fiunt (Alles ist das Werk des Zufalls)
Zufall spielt in der Biologie eine riesige Rolle. Die Grundlage der Evolution, nämlich Mutationen, die zu Veränderungen in unserem Erbgut führen, sind zufällig. Ereignisse sind zufällig, wenn es keine Ursache als Erklärung für das Ereignis gibt. Mutationen haben zwar durchaus eine Ursache (zum Beispiel UV-Strahlung), das Zusammentreffen der Ereignisse ist aber zufällig. In der Informatik gibt es Algorithmen, die den Zufall nutzen um schwer lösbare Probleme bewältigen zu können. Schwer lösbare Probleme zeichnen sich vor allem dadurch aus, dass die Algorithmen extrem lange rechnen, um zu einer Lösung zu kommen. In dem man zufällige Schritte in den Algorithmus einbaut, kann man auf zwei Wegen Abhilfe schaffen: man verzichtet unter Umständen auf die ganz exakte Lösung oder aber man hat zufällig Glück (oft) und der Algorithmus ist schnell oder Pech (selten) und der Algorithmus ist langsam.
Das sind nur zwei Beispiele für Prinzipien, die sich Biologie und Informatik teilen. Es gibt noch viel mehr solcher Prinzipien und Ideen, die sich die eine Wissenschaft von der anderen abschauen kann. Die große Kunst der Bioinformatik ist es, beide Disziplinen zusammenzuführen und dadurch beide Wissenschaften voranzutreiben.

Kommentare (30)