Nachdem im letzten Artikel (ich muss dringend an den Update-Zyklen arbeiten…) geklärt wurde, wie ein einzelner Punkt mit Hilfe von Matrizen so transformiert werden kann, dass er auf den Bildschirm gezeichnet werden kann, wollen wir uns heute damit beschäftigen, wie mit Hilfe dieser Technik ganze Objekte statt nur einzelner Punkte darstellbar sind. Natürlich ist es auch diesmal nicht ganz so einfach und es wird vorher noch etwas Mathematik benötigt, um die gewünschten Objekte nachher auch wirklich zeichnen zu können. Aber eins nach dem anderen.
Zur Darstellung von Objekten mit Hilfe von im Raum liegenden Punkten auf dem Bildschirm gibt es verschiedene Verfahren; die beiden Hauptverfahren habe ich beim letzten mal schon angedeutet. Zum einen wäre das die Verwendung sogenannter Punktwolken, bei denen die darzustellenden Objekte komplett durch viele Einzelpunkte beschrieben werden; diese Punkte – und damit das darzustellende Objekt – können mit dem bereits beschriebenen Verfahren auf den Bildschirm gezeichnet werden. Das funktioniert, hat aber den Nachteil, dass es relativ Speicher- und Rechenaufwändig ist, um die Detailgenauigkeit hinzubekommen, die gewünscht wird (auf Grund steigender Rechenkapazitäten ist es aber wahrscheinlich, dass dieser Ansatz in den nächsten Jahren verstärkt verfolgt wird). Momentan wird daher eher auf Polygonnetze (englisch Polygon Meshes, kurz Meshes) gesetzt.
Kurz zur Theorie: ein Polygon ist ein Vieleck, also eine Menge durch einen Linienzug verbundener Punkte. Das einfachste Polygon ist das allseits bekannte Dreieck, welches folgerichtig durch drei Punkte bestimmt wird. Derartige Dreiecke lassen sich relativ leicht auf den Bildschirm zeichnen (wie, sehen wir gleich noch), weswegen sie in der Computergrafik gern benutzt werden, um Objekte darzustellen. Zu diesem Zweck wird die Oberfläche eines Objektes durch eine Menge miteinander verbundener Dreiecke, das Polygonnetz, beschrieben; die Anzahl der verwendeten Dreiecke bestimmt dabei, wie detailliert ein Objekt beschrieben wird – je mehr Dreiecke, desto mehr Details. Unsere Szene aus dem letzten Artikel mit Dreiecken dargestellt würde etwa so aussehen (man spricht bei derartigen Darstellungen vom Drahtgittermodell, da es wirkt, als wären die Objekte aus dünnen Drähten aufgebaut):
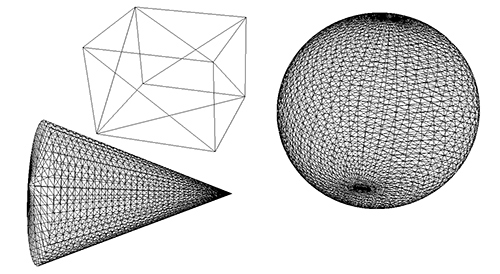
Zu beachten ist, dass der Würfel aus wenigen Dreiecken (konkret: 12) besteht, der Kegel und die Kugel dagegen aus einer ungleich größeren Menge; würden Kugel und Kegel aus weniger Dreiecken bestehen, wären sie nicht mehr so schön “rund”, sondern eher eckig und kantig – ganz so, wie man die Grafik aus älteren 3D-Computerspielen gewöhnt ist.
Nun wissen wir zwar, wie sich die Form eines Objektes durch Dreiecke beschreiben lässt (über Farben reden wir ein andermal), aber es bleibt immer noch die Frage, wie diese Dreiecke am Ende auf den Bildschirm kommen. Genau hier kommt nun die Technik zum Einsatz, die dem ganzen Verfahren seinen Namen gegeben hat, nämlich die Rasterung (engl. Rasterisation). Unter diesem Begriff werden mehrere Methoden zusammengefasst, um geometrische Objekte in eine Rastergrafik, also in ein aus Pixeln bzw. Punkten bestehendes Bild, umzuwandeln.
Die einfachste Methode der Rasterung ist natürlich das Zeichnen von Punkten; hierbei wird ein in Bildschirmkoordinaten vorliegender Punkt (also ein Punkt mit einer Angabe für die Position in Breite und Höhe) einfach in das Raster gesetzt (wie das funktionierte, wurde bereits hier beschrieben).
Der nächste Schritt wäre nun die Rasterung von Linien; das ist mathematisch ein wenig anspruchsvoller, aber immer noch recht einfach umzusetzen. Zur Rasterung einer Linie wird ihre geometrische
Beschreibung, bestehend aus Anfangs- und Endpunkt der Linie, als Grundlage für den Zeichenvorgang benutzt. Das einfachste Verfahren ist, die zu zeichnende Linie durch ihre Geradengleichung1 zu beschreiben. Wir erinnern uns aus der Mathematik: eine Linie wird in der Geradengleichung durch ihren Anstieg m und einen Punkt (xs,ys) auf der Linie beschrieben (auch bekannt als Einpunktform):
y = m * ( x – xs ) + ys
1 An dieser Stelle ein kurzes Wort zur Terminologie: eine Strecke ist eine gerade Linie, die von 2 Punkten begrenzt wird. Eine Gerade ist eine unendlich lange gerade Linie. Der englische Ausdruck für “Strecke” ist “line segment” – ich werde daher auch im Deutschen von Liniensegmenten reden.
Übersetzt heißt das: jeder y-Wert einer Linie (die Höhe des Punktes) kann berechnet werden, indem der zugehörige x-Wert (die Breite des Punktes) in die Gleichung eingesetzt wird. Die Steigung m der Geraden kann berechnet werden, sobald wenigstens 2 Punkte bekannt sind; bei einem Liniensegment sind das für gewöhnlich der Anfangspunkt ( xs, ys ) und der Endpunkt ( xe, ye ); m berechnet sich dann aus folgender Formel:
m = ( ye – ys ) / ( xe – xs )
Mit diesen Informationen lässt sich nun ein durch Start- und Endpunkt gegebenes Liniensegment auf den Bildschirm zeichnen. Da Pixel-Koordinaten immer ganzzahligen Werten entsprechen (sprich, 1, 2, 3 usw., aber nie zum Beispiel 1,5), muss man zum Zeichnen der Linie lediglich alle x-Werte zwischen Anfangs- und Endwert durchlaufen, für jeden den zugehörigen y-Wert berechnen und den so berechneten Pixel auf dem Bildschirm einfärben. Da für die y-Werte natürlich nicht zwangsläufig immer ganzzahlige Werte herauskommen, hilft einfaches Auf- bzw. Abrunden.
Schauen wir uns ein kurzes Beispiel an. Nehmen wir als Startpunkt des zu zeichnenden Liniensegments etwa den Punkt (1,1) und als Endpunkt den Punkt (9, 4). Aus diesen beiden Punkten lässt sich der Anstieg der Geraden folgendermaßen berechnen:
m = ( 4 – 1 ) / ( 9 – 1 ) = 3 / 8 = 0,375
Die Geradengleichung lautet demzufolge (wobei man genauso gut den Endpunkt als Referenzpunkt benutzen könnte):
y =
0,375
* ( x – 1 ) + 1
Nun muss für alle x-Werte von 1 bis 6 der zugehörige y-Wert berechnet werden; gerundet ergeben sich die folgenden Wertepaare (x,y):
(1,1), (2,1), (3,2), (4,2), (5,3), (6,3), (7,3), (8,4), (9,4)
Diese Pixelkoordinaten bilden das gerasterte Liniensegment; in ein Raster (also z.B. den Bildschirm) gezeichnet würden sie so aussehen (in Grau die Punkte, in Schwarz die originale Strecke zum Vergleich); Achtung: der Koordinatenursprung liegt informatikgerecht natürlich bei (0,0):
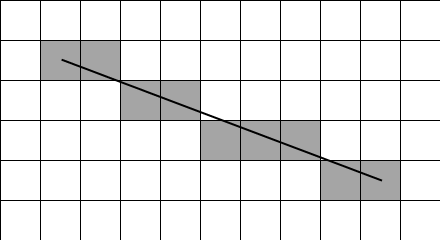
Man sieht, dass die gerasterten Punkte eine recht gute Annäherung an das eigentliche Liniensegment darstellen. Natürlich wirkt es ein wenig grob und eckig; es gibt zwar ausgefeilte Algorithmen, die diese Kante glätten können (Freunde von Computerspielen werden das als Antialiasing kennen), aber die sollen hier nicht weiter interessieren.
Da wir ja bereits im letzten Artikel geklärt haben, wie sich einzelne Punkte aus Welt- (3-dimensional) in Bildschirm-Koordinaten (2-dimensional) umrechnen lassen, haben wir jetzt das benötigte Handwerkzeug zusammen, um komplexe Objekte auf dem Bildschirm darstellen zu können. Ein Objekt wird, wie bereits erwähnt, durch eine Menge von Dreiecken beschrieben. Ein Dreieck ist aber nichts anderes als 3 Liniensegmente, die durch die drei Eckpunkte des Dreiecks begrenzt werden. Um also ein Dreieck auf den Bildschirm zu zeichnen, reicht es, die drei zugehörigen Linien zu zeichnen (durch dieses Verfahren ist auch das erste Bild im Artikel entstanden).2 Ein simples Beispiel hierzu (ohne Rechenweg), welches 4 Dreiecke zeigt (den Rest des Würfels möge man sich einfach denken):
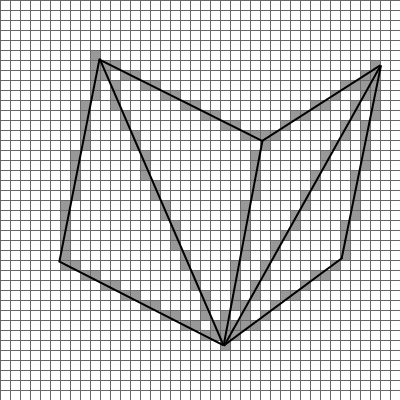
Aufmerksame Leser werden nun bemerken, dass ich ja eigentlich davon gesprochen hatte, dass für jeden x-Wert zwischen Start- und Endpunkt des Liniensegments ein y-Wert berechnet wird. Es sollte also nicht der Fall sein können, dass für ein Liniensegment einem y-Wert mehrere x-Werte zugeordnet sind; offensichtlich ist das aber in der Abbildung der Fall und auch gar nicht vermeidbar, um vernünftig Linien darstellen zu können. Der Trick dabei ist: sobald der Anstieg eines Liniensegmentes größer ist als 0,5 (oder kleiner als -0.5), wird die Geradengleichung einfach nach y umgestellt und stattdessen für jeden y-Wert zwischen Start- und Endpunkt ein x-Wert berechnet.
Am Bild ist übrigens auch gut zu erkennen, warum eine höhere Auflösung (das heißt, mehr gezeichnete Pixel in Breite und Höhe) gern gesehen wird: das Bild wird dadurch nämlich viel feiner und wirkt nicht so blockig wie obiges Beispiel.
Zugegeben, das Objekt an sich haben wir damit natürlich nicht gezeichnet, sondern lediglich sein Drahtgittermodell. Uns fehlt nämlich noch die Möglichkeit, nicht nur die Umrandung der Dreiecke zu zeichnen, sondern die Dreiecksfläche auch zu füllen. Aber darum soll es erst im nächsten Artikel gehen.
2 Ganz so einfach ist es natürlich wie immer nicht. Das beschriebene Verfahren ist zwar eine Möglichkeit, wäre aber natürlich sehr rechen- und speicheraufwendig, da viele Punkte im Drahtgittermodell durch mehrere Dreiecke berührt werden und sich viele Dreiecke auch mehrere Liniensegmente Teilen. Für eine effiziente Verarbeitung werden daher die Dreiecke in einer speziellen Struktur gespeichert, einer sogenannten indizierten Dreiecksliste. Wenn genügend Interesse besteht, nehme ich die Beschreibung der Dreieckslisten in einen zukünftigen Artikel auf oder lege einen separaten dafür an.
Kommentare (7)