
Forschung ist kompliziert. Das ist trivial, aber dennoch einen genaueren Blick wert. Denn genau darum geht es: Um den genauen Blick. Ganz klassisch wird die Methodik der Wissenschaft ja gerne so zusammengefasst: Man stellt eine Hypothese auf. Dann wird die Hypothese anhand von Daten geprüft. Und danach entweder verifiziert oder verworfen. Dieser Prozess funktioniert sehr gut. Aber eben manchmal auch nicht. Manchmal verhindert die Hypothese, dass man das sieht, was wirklich da ist – zum Beispiel ein Daten-Gorilla.
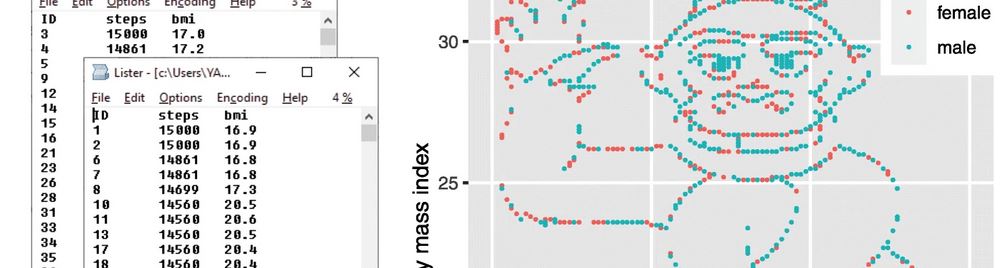
Itai Yanai vom New York University Langone Medical Center und Martin Lercher von der Uni Düsseldorf haben ein recht interessantes Experiment gemacht (“A hypothesis is a liability”). Sie haben Studierenden einen Haufen Daten gegeben. Es war ein recht simpler Datensatz: Der Body-Mass-Index (BMI) von 1786 Menschen und dazu die Anzahl der Schritte die die jeweiligen Personen an einem bestimmten Tag gegangen sind. Ein Datensatz für die Männer, einer für die Frauen. Die Studierenden wurden in zwei Gruppen geteilt. Die erste Gruppe bekam die Aufgabe, die Daten auf drei verschiedene Hypothesen zu prüfen. Erstens: Es gibt einen statistisch relevanten Unterschied in der durchschnittlichen Anzahl der Schritte bei Männer und Frauen. Zweitens: Es gibt eine negative Korrelation zwischen der Anzahl der Schritte und dem BMI bei Frauen. Drittens: Die gleiche Korrelation ist bei Männern positiv. Außerdem wurden sie gefragt, ob in den Daten sonst noch was interessantes zu finden sei. Die zweite Gruppe der Studierenden bekam keine Hypothesen präsentiert; sie wurde einfach gefragt was man aus diesen Daten ableiten könne.
Jetzt wäre es prinzipiell ja interessant zu wissen, ob die Anzahl an Schritten die man täglich geht eine Auswirkung auf den BMI hat und ob sich dieser Zusammenhang bei Männer und Frauen unterschiedlich darstellt. Nur konnte man das definitiv nicht aus den Daten ablesen. Die haben Yanai und Lercher nämlich ganz speziell zusammengestellt. Wenn man die Daten von Männern und Frauen kombiniert und in einem Diagramm auf der x-Achse die Schritte aufträgt und auf der y-Achse den BMI: Dann sieht man einen winkenden Gorilla! Nicht irgendwie versteckt, sondern sehr deutlich. Da gibt es keinen Interpretationsspielraum:

Die eigentliche Frage der Forscher war also: Finden die Leute bei ihrer Analyse den Gorilla? Das erinnert nicht zufällig an das berühmte Gorillaexperiment von Daniel Simons und Christopher Chabris mit dem die “Unaufmerksamkeitsblindheit” demonstriert werden soll. Versuchspersonen bekamen ein Video gezeigt mit Menschen die sich einen Ball zuwerfen. Sie sollten die Pässe zählen, was sie auch taten – dabei aber komplett übersehen haben, dass sehr gut sichtbar ein Mensch in einem Gorillakostüm durchs Bild läuft.
In der abstrakteren Variante von Yanai und Lercher war die Frage: Verpassen wir etwas relevantes bei der Analyse von Daten wenn wir uns schon vorab für bestimmte Hypothesen entscheiden die die Daten belegen/wiederlegen sollen? Die Antwort: Ja, tun wir! Es war fünfmal wahrscheinlicher dass die Studierenden ohne Hypothese-Vorgabe den Daten-Gorilla entdecken als dass er von der Gruppe gefunden wurde, die versuchten die drei konkreten Hypothesen zu untersuchen.
Es wäre nicht schwer gewesen, den Gorilla zu sehen. Man hätte einfach nur die Rohdaten visualieren müssen; ein Prozess zu dem kein großer Aufwand nötig ist; die Bedeutung von Visualisierungen wurde den Studierenden auch in ihrem Studium beigebracht. Aber wenn man einer Hypothese auf der Spur ist, verliert man offensichtlich den Blick fürs Große ein wenig und konzentriert sich gleich auf die nötigen Details um die Vermutung bestätigen zu können. Wenn man hingegen einfach nur “mal schauen” soll, was die Daten hergeben, dann geht man etwas spielerischer an die Sache heran und probiert alle möglichen Dinge aus.
Der Titel der Arbeit von Yanai und Lercher lautet “A hypothesis is a liability”, also “Eine Hypothese ist eine Belastung”. Ich bin damit aber nicht ganz einverstanden. Die Sache ist ein wenig komplexer. Denn wenn man einfach auf gut Glück mit Daten rumbastelt, kann man zwar einerseits Dinge finden, die man sonst nie gefunden hätte. Andererseits aber auch Phänomene entdecken die es gar nicht gibt. Wie bei der “Schokolade hilft beim Abnehmen”-Studie aus dem Jahr 2015: Die war absichtlich schlecht gemacht um die Methoden des schlechten Wissenschaftsjournalismus aufzuzeigen – benutzt aber Techniken die leider auch in der echten Forschung (absichtlich oder unabsichtlich) vorkommen. Wenn man etwa einfach nur genug Datenpunkte sammelt und die auf so viele mögliche Arten miteinander kombiniert, dann findet man früher oder später immer irgendwas, was nach einem realen Zusammenhang aussieht, aber keiner ist. In diesem Fall eben “Schokolade hilft beim Abnehmen”. Das nennt sich übrigens “p-Hacking” und “funktioniert” deswegen, weil man sich vor der Forschung nicht darauf festlegt, was man eigentlich wissen will und so nachträglich die Parameter der Analyse anpassen kann.
Wenn man wissenschaftlich seriös arbeiten will, dann sollte man schon darauf achten, halbwegs einen Plan zu haben. Man sollte wissen, welche Fragen man beantworten möchte und wie man das anstellen kann. Gleichzeitig – und genau darauf weist die Studie von Yanai und Lercher mit dem Daten-Gorilla hin – muss man aber immer offen für Antworten auf Fragen sein, die man gar nicht gestellt hat! Das gelingt der Wissenschaft im großen und ganzen recht gut. Aber leider wissen wir ja nicht, welche Gorillas wir bis jetzt verpasst haben…










Kommentare (21)