
Nach diesem Ausflug in die frühe Welt der Textverarbeitung, wie ich sie in Erinnerung habe, wieder zurück zu den Zeichensätzen. Denn damit kann man auch heute noch Probleme kriegen, wenn da irgendwas nicht richtig eingestellt ist. Nehem wir zum Beispiel die DOS-Codepage 850. Das ist jene Seite, die die Anpassungen des Zeichensatzes für Westeuropa enthält. Darin gibt es so schöne Symbole um Rahmen zu “zeichnen”:
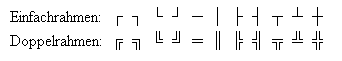
DOS-Rahmensymbole, Eigenes Werk

Bildschirmmaske aus den Rahmensymbolen der DOS-Codepage 850, Eigenes Werk
Der hauptsächliche Zweck dieser Maske besteht darin, möglichst alle Rahmensymbole zu verwenden. Was für ein Programm die verwenden könnte, weis ich auch nicht so wirklich, ist hier aber auch nicht wichtig. Interessant ist eher noch, dass das Bild genau 640 x 400 Pixel gross ist, und damit genau die Grösse hat, die auf einem damals üblichen 14-Zoll Monitor gut darstellbar war. Wenn man diese Maske aber für ein Programm unter Windows übernehmen wollte (was zwar nicht viel Sinn macht, aber darum geht’s ja nicht), dann bekommt man ein Problem, denn dann sehen die Zeichencodes, die unter DOS noch für die Rahmensymbole standen, auf einmal so aus:
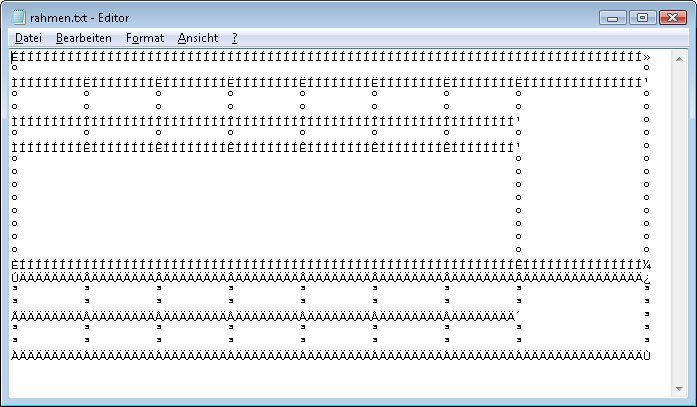
Selbsterstellter Screenshot
Was ist hier passiert? – Nun Windows verwendet einen anderen Code, d.h. den Codes werden andere Zeichen zugeordnet. In diesem Fall nennt er sich Windows-1252. Dabei handelt es sich um eine Microsoft-spezifische Variante von ISO-8859. Das wiederum ist ein 8-Bit Code, der von der Internationalen Organisation für Normung, kurz “ISO” erarbeitet wurde. Man kann also sagen, dass er einen Versuch darstellt, den Wildwuchs von Erweiterungen des ASCII-Codes international zu vereinheitlichen. Die Zuordnungen von 0 (Null) bis 127 entsprechen dabei im wesentlichen dem ASCII-Code, die Zuordnungen von 128 bis 255 werden durch ISO-8859 neu definiert. Da man damit aber nicht alle europäischen Sprachen abdecken kann, gibt es ISO-8859 in 15 “Geschmacksrichtungen“, die durch anhängen von “-X” an die Normbezeichnung gekennzeichnet sind. X ist eine Zahl zwischen 1 und 16 ist, wobei aus irgendeinem Grund die 12 aussenvor bleibt. Deshalb 1 bis 16 und nicht 1 bis 15. Der für Westeuropa definierte Teil nennt sich ISO-8859-1.
Aus einem weiteren Grund, der AFAIK was mit Erleichterungen bei der Softwareentwicklung zu tun hat, hat die ISO den Bereich von 128 bis 159 leer gelassen. D.h. diesen Codes sind keine Zeichen zugeordnet. Und nun wäre Microsoft nicht Microsoft, wenn die das nicht ausgenützt hätten. So haben die bei MS den Bereich von 128 bis 159 mit einigen Zeichen gefüllt, die sie für besonders nützlich hielten und diesen Erweiterungen eigene Nummern zugewiesen. Das sind u.a. die Windows-Codepages 1250 bis 1258, für Westeuropa ist es die Nummer 1252, die auch in Deutschland verwendet wird.
Und wer von diesem ganzen Zahlensalat jetzt reichlich verwirrt ist, dem kann ich leider nicht helfen, denn es geht noch weiter. Da ISO-8859 ein 8-Bit-Code ist, kommt man damit vielleicht in Europa aus, aber eben auch nicht überall. Um nun aber Weltweit Daten austauschen zu können, insbesondere über Netzwerke wie das Internet, hat man schon um 1989 herum angefangen, einen Standard zu erarbeiten, der auf der ganzen Welt benutzt werden kann. Der nennt sich Unicode und war in der ersten Version, die 1991 erschienen ist, 16 Bit breit. Seit Version 2.0 von 1996 ist das gesamte System 21 Bit breit, die man aber kaum alle gleichzeitig brauchen wird. Man sucht sich vielmehr die Sprachen und zugehörigen Schriftsysteme aus, die man braucht und das Betriebssystem sorgt dann dafür, das man damit arbeiten kann. Dabei werden die verwendeten Zeichen innerhalb des Rechners nur mit 16 Bit codiert. Um das zu ermöglichen, gibt es innerhalb des Unicodessystems geeignete Methoden, mit denen sich die benötigten Codebereiche aus dem 21 Bit breiten Bereich innerhalb von 16 Bit darstellen lassen. Wie das im Detail funktioniert, würde diesen Beitrag sprengen, denn das ganze System ist so umfangreich, dass man sich Wochen- oder Monate lang damit befassen kann. Allein die Dokumentation umfasst mehrere hundert Seiten. Dazu kommen noch viele Seiten Anhang, aus denen man die Codes für jedes der 1.114.112 definierten Zeichen entnehmen kann. Wer mehr darüber wissen will, möge sich auf den Webseiten des Unicode-Konsortiums umsehen.
Hier ist in diesem Zusammenhang nur noch das Unicode Transformation Format, kurz UTF interessaant, denn das ist eine der im Internet verwendeten Methoden, Unicode-Zeichen als Bytefolgen darzustellen. Wer sich schon mal intensiver mit Webdesign beschäftigt hat, dem wird das folgende bekannt vorkommen:










Kommentare (46)