
Hinweis: Dieser Artikel ist ein Beitrag zum ScienceBlogs Blog-Schreibwettbewerb 2015. Hinweise zum Ablauf des Bewerbs und wie ihr dabei Abstimmen könnt findet ihr hier. Informationen über die Autoren der Wettbewerbsbeiträge findet ihr jeweils am Ende der Artikel.

——————————————
Es dürfte allgemein bekannt sein, dass alle Informationen, die im Computer verarbeitet werden, intern aus Nullen und Einsen bestehen. Dabei ist es egal, ob es sich um Texte, Bilder, Klänge oder Videos handelt. Alles besteht Computerintern aus Nullen und Einsen. Die Frage, wie sich aus diesen Nullen und Einsen dann Texte, Bilder oder Klänge ergeben, können schon wesentlich weniger Leute beantworten. Ich will hier auf den Teil näher eingehen, der sich mit Texten befasst, denn das Thema ist Umfangreicher, als es zunächst erscheint.
Fangen wir mal mit der Schreibmaschiene an. Wie die mechanisch funktioniert möge man in der Wikipedia oder sonstiger einschlägiger Literatur nachlesen. Hier interessiert nur, das es für jeden Buchstaben eine Art Stempel (Type genannt) gab, mit dem ein Zeichen durch ein Farbband auf’s Papier gedruckt wurde. Wenn man nun vom lateinischen Alphabet, bzw. von lateinischer Schrift ausgeht, kommt man inklusive Satzzeichen zunächst einmal auf unfähr 80 Symbole. Das sind: 26 GROSSBUCHSTABEN, 26 kleinbuchstaben, 10 Ziffern, 7 Satzzeichen (Punkt, Komma, Fragezeichen, Ausrufezeichen, Doppelpunkt, Semikolon, Anführungszeichen) und 10 weiteren Sonderzeichen: + – * / % & § = sowie öffnende und schliessende Klammern. Man kann davon ausgehen, dass gerade von den Satz- und Sonderzeichen nicht alle auf einer Schreibmaschiene vertreten waren, wobei ich das aber auch nicht überprüfen kann.
Um nun mit dem Computer einen Text zu verfassen, stellte sich die Frage, wie man denn nun die einzelnen Zeichen im Rechner darstellt. Dazu gab es verschiedene Lösungen. Die bekannteste, die auch heute noch verwendet wird, nennt sich ASCII-Code. ASCII ist dabei eine Abkürzung und steht für “American Standard Code for Information Interchange”, was auch gleich etwas über die Herkunft des Codes aussagt. Diese Anspielung auf die Herkunft wird spätestens dann bedeutungsvoll, wenn man damit bestimmte Zeichen aus europäischen Sprachen darstellen will, die im Englischen nicht üblich sind. Dazu komme ich später noch.
Der ASCII-Code ist, wie jeder andere Code auch, eine Zuordnung: Jedem Zeichen, sei es nun Buchstabe, Ziffer, oder sonstiges Zeichen wird eine Zahl zugeordnet, und der Computer erkennt anhand dieser Zahl, welches Zeichen er darstellen soll. Nun ist der ASCII-Code aber auch ein Kind seiner Zeit, nämlich der 1960er Jahre. Da gab es noch kein Internet, dafür waren aber sogenannte Fernschreiber weit verbreitet, die es heutzutage kaum noch gibt. Die kann man sich in etwa als Schreibmaschiene mit Anschluss ans Telefonnetz vorstellen, womit man einen Text über eine Kommunikationsleitung an ein entferntes Gerät verschicken konnte. Das war so ähnlich wie email oder eher FAX, weil eine Nachricht, wenn sie irgendwo ankam, gleich auf Papier gedruckt wurde. Um diesen Fernschreibern auch mitteilen zu können, wann eine neue Zeile zu nehmen ist, eine Seite oder die gesamte Nachricht zu Ende ist, gibt es im ASCII-Code eine Reihe sogenannter Steuerzeichen. Die dienen dazu, dem Fernschreiber genau solche Dinge mitzuteilen.
Von diesen Steuerzeichen gibt es genau 32 Stück, wovon heutzutage noch etwa 8 Stück in PCs verwendet werden. Der Rest ist von der technischen Entwicklung überholt. Man könnte die Steuercodes zwar auch heute noch verwenden, aber die Aufgaben, für die sie einmal gedacht waren, werden inzwischen anders gelöst. Weil Fragen der Datenübertragung und deren mögliche Lösungen, die diese Steuercodes einst waren, auch heute noch ein Forschungsgebiet in der Informatik und Nachrichten(übertragungs)technik sind, gehe ich da nicht weiter drauf ein.
Kommen wir also zu den druckbaren Zeichen. Wie der Name schon sagt, sind das jene Zeichen, die sich auf dem Papier wiederfinden lassen. Der ASCII-Code kennt davon 95 Stück. Das sind neben den oben erwähnten u.a. die eckigen und geschweiften Klammern, also [] und {}. (Letztere dürften aus dem Matheunterricht auch als “Mengenklammern” bekannt sein.) Dazu kommen noch der umgedrehte Schrägstrich “\”, auch als Backslash bezeichnet, das “Lattenkreuz” #, der Klammeraffe @, das Dollarzeichen $ und ein paar andere.
Insgesamt sind das 128 verschiedene Zeichen (wenn man die Null noch dazu nimmt, die zwar als Nullbyte vorhanden ist, aber sonst keine Bedeutung hat). Nun ist 128 auch eine glatte 2er-Potenz, nämlich das Ergebnis von zwei hoch sieben, auch als 27 oder 2^7 geschrieben. – Zahlen müssen ja auch irgendwie codiert werden. Die Codierung von Zahlen erfolgt dabei nach dem Dual- oder Binärsystem, womit sie als Potenzen von 2 dargestellt werden. Wer damit nicht vertraut ist, möge z.B. hier (klick) nachsehen.
Weil man für alle Zeichen des ASCII-Codes mit 7 binären Stellen auskommt, spricht man auch von einem 7-Bit Code. Ein Bit ist die kleinste darstellbare Grösse im Computer, die entweder Null oder Eins sein kann, womit wir bei den eingangs erwähnten Nullen und Einsen sind, aus denen sich alle Informationen im Computer zusammen setzen. Um mit den Bits besser hantieren zu können, fasst man sie zu Gruppen zusammen, die man als Byte bezeichnet. So ein Byte besteht aus 8 Bits und ist jene Einheit, mit der man unter anderem die Speicherkapazität eines Computers, oder auch den Speicherbedarf von Daten und Programmen angibt. Dann oft mit einer Vorsilbe wie Kilo, Mega oder Giga versehen.
Dieser Text z.B. umfasst bis zum vorherigen Satz z.B. 5374 Bytes, was etwas über 5 KiloByte entspricht.
Hinter diesen 5374 Bytes verbergen sich aber auch 5374 Zeichen. Die sind allerdings nicht alle ASCII-codiert. Denn der ASCII-Code kennt z.B. keine deutschen Umlaute und auch das im deutschen verbreitete ß; auch “scharfes S” oder “Buckel S” genannt, ist im ASCII-Code unbekannt. Warum auch? – denn diese Zeichen gibt es in der englischen Schriftsprache ja auch nicht. könnte man jetzt sagen. Hat man in der Vergangeheit wohl auch eine Zeit lang gemacht. Das führte zu einem Wildwuchs an Erweiterungen für jene Länder, in denen etwas anderes als Englisch gesprochen wird, wie z.B. im deutschsprachigen Raum. Wer die Heimcomputerära der 1980er Jahre miterlebt hat, wird davon noch ein Lied singen können… – Aber der Reihe nach: Der ASCII-Code umfasst 7 Bits, womit 27 = 128 verschiedene Zeichen zur Verfügung stehen. Da ein Byte aber aus 8 Bits besteht und 28 = 256 ergibt, kann man weitere 128 Zeichen definieren. (2*128 = 256).
Das ist in der Vergangenheit auch gemacht worden und ergab dann für jedes Land eine eigene Erweiterung oder eine Erweiterung für Länder mit ähnlichen Schriftzeichen. Zu nennen wären da etwa die romanischen Sprachen wie Französich und Spanisch oder die skandinavischen Sprachen. Alle diese haben auch ihre besonderen Symbole in der Schriftsprache, so etwa die Akzente über den Selbstlauten (é, ò, â) und “der Haken” (Cedille) unter dem C (ç) im Französichen oder so Sachen wie Ø oder æ in skandinavischen Sprachen. Oder das Symbol für das britische Pfund: £.
Nun konnte aber auch nicht jedes Land für sich die Norm ändern, denn die wichtigste Software eines jeden Computers, nämlich das Betriebssystem kam auch damals schon aus den USA. Also waren die US-Softwarehersteller angehalten, eine Lösung zu finden, wenn sie weiter erfolgreich exportieren wollten. Bei den Betriebssystemen hat man sich dazu die sogenannten Codepages ausgedacht, die für einzelne Länder oder sprachlich abgrenzbare Regionen entsprechende Anpassungen enthielten. Die Codes für diese Zeichen sind alle grösser als 128, “erweitern” den ASCII-Code also, indem sie den Werten zwischen 128 und 256 neue Zeichen zuordnen.
Einen Sonderfall bei den Heimcomputern stellte die Firma Commodore dar, denn die hat sich nicht so genau an die ASCII-Norm gehalten, bzw. diese ein wenig umdefiniert. So gab es etwa auf dem C64/128 zwei Modi zur Zeichendarstellung, wovon der eine nur Grossbuchstaben kannte. An der Stelle, wo die Kleinbuchstaben sein sollten, fanden sich grafische Symbole, die spezifisch für Commodore waren. Wenn man den Darstellungsmodus umgeschaltet hat, wurden GROSSBUCHSTABEN zu kleinbuchstaben und aus einigen Grafiksymbolen wurden Grossbuchstaben. Das führte schon mal zu Verwirrung, wenn man den Darstellungsmodus versehentlich umgeschaltet hat. (Dazu musste man zwei übereinander liegende Tasten gleichzeitig drücken.) Oder wenn man etwas drucken wollte und der Drucker nicht richtig konfiguriert (eingestellt) war. Und natürlich, wenn man Daten zwischen Heimcomputer und PC austauschen wollte oder musste. Die Zeichen sahen auf dem C64 übrigens so aus:

Die beiden Zeichensätze des C64 nebeneinander. Man sieht, wie aus kleinen Buchstaben Grosse werden (erste zwei Zeilen), und aus grossen Buchstaben grafische Symbole. (5. und 6. Zeile im Bild.) Bild: gemeinfrei
Von dieser Anekdote nun zu der Frage, wie oder wo denn genau festgelegt ist, wie ein Zeichen aussehen soll? – Wir haben bisher den ASCII-Code kennen gelernt und dass es dazu diverse, meisst länderspezifische Erweiterungen gab. Aber letztlich werden den einzelnen Zeichen dabei nur Nummern zugewiesen. Wie ein Zeichen auf dem Bildschirm oder dem Drucker jedoch aussehen soll, darüber sagt der Code genau garnichts aus. Bei der Schreibmaschiene war das Aussehen durch die Type vorgegeben, die entweder am Typenhebel oder bei späteren Geräten auf dem Typenrad angebracht waren. Typenräder konnte man sogar austauschen, wenn man ein anderes Schriftbild haben wollte. Und beim Computer? – Da gibt es einen speziellen Speicherbereich, der Zeichengenerator genannt wird. In diesem Speicher ist für jedes darstellbare Zeichen ein Muster abgelegt, das die Form eines Zeichens festlegt. So ein Muster ist ein quadratisches oder rechteckiges Feld aus Punkten. So einem Punkt kann der Wert Null oder Eins zugewiesen sein. Eine Null bedeutet, dass der Punkt die Farbe des Hintergrundes annimmt, eine Eins, dass der Punkt die Farbe des Vordergrundes, also der Schriftfarbe annimmt.
Diese Zeichenmuster werden auch Zeichenmatrizen genannt und waren oftmals genau 8 x 8 Punkte gross, später wurden die Zeichen höher und hatten 12, 14 oder 16 Punktzeilen, waren aber immer noch 8 Spalten breit. In speziellen Fällen auch 9, aber das lassen wir jetzt mal.
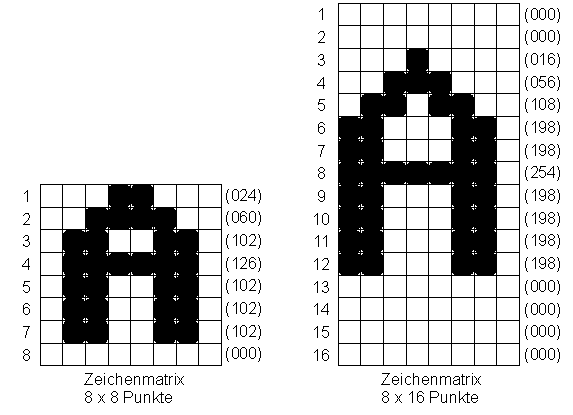
Zeichenmatrizen, wie sie im C64 und beim PC auf der VGA-Karte definiert sind.
Quelle: Nach einer Vorlage aus “Commodore 128 Intern” (ISBN: 3-89011-098-3) und dem Zeichen-ROM meiner Grafikkarte selbst erstelltes Werk.
Die 8×8-Matrix zeigt das “A” so, wie es ein C64 darstellt. Die 8×16 Matrix hab ich so aus dem Charakter-ROM meiner Grafikkarte ausgelesen. Character-ROM ist eine andere Bezeichnung für den Zeichengenerator. Die Zahlen links von der Skizze geben dabei die Nummer der Zeile an und die Zahlen in den Klammern rechts die dezimale Darstellung des Bytes, das man für das Bitmuster dieser Zeile im Speicher findet. Die Zeichen sind also Zeilenweise definiert, wobei sich die Breite der Zeichen an der breite eines Bytes orientiert.
Bei dieser Sammlung der Formen die festlegen, wie einzelne Zeichen aussehen sollen, spricht man auch von einem Zeichensatz (englisch: font). Der Zeichensatz gibt also Auskunft darüber, wie einzelne Zeichen aussehen sollen, die durch Codes wie den ASCII-Code bestimmt werden.
Mit diesen vorgegeben Zeichensätzen kam man in der Anfangszeit der Compuer meistens auch aus, denn die damals hauptsächlich verwendeten Terminals, mit denen man am Rechner arbeitete, konnten nichts anderes. Sie bekamen vom angeschlossenen Rechner Anweisungen, welche Zeichen sie darstellen sollten, wozu der Rechner die ASCII-Codes übermittelt hat. Die Terminals haben dann die durch den Code festgelegten Zeichen angezeigt, deren Form sie einem Zeichengenerator entnommen haben.
Die ersten IBM-PCs arbeiteten so ähnlich. Der Unterschied war, dass es dort kein Terminal war, das für die Darstellung am Bildschirm zuständig war, sondern eine Grafikkarte. Der Begriff “Grafikkarte” ist in diesem Fall allerdings irreführend, denn die sogenannten MDA-Karten, die in den ersten IBM-PCs eingebaut waren, konnten gar keine Grafik darstellen. Korrekterweise nannte man sie deshalb auch Bildschirmadapter. Diese Bildschirmadapter hatten die weitere Einschränkung, dass sie auch keine Farben darstellen konnten, sondern auf eine Farbe festgelegt waren. Die konnten die Anwender aber durch die Wahl des Monitors bestimmen. Man konnte zwischen Grün und Bernsteinfarben wählen. Da die Monitore also auch nicht viel mehr konnten, nannte man sie Monochrom-Monitore. Das MDA in obiger Kartenbezeichnung steht entsprechend für Monochorme Display Adapter.
Nun gab es zu der Zeit, als der erste IBM-PC auf den Markt kam, also 1982, aber schon Computer, die nicht nur Farbe darstellen konnten, sondern auch Grafik. Das waren in vielen Fällen die sogenannten Heimcomputer, die man damals streng von den Personal Computern unterschieden hat. So war jedenfalls meine Wahrnehmung, obwohl sich auch der C64/128 oder die Schneider CPCs als Personal Computer bezeichneten. Aber ich schweife ab. Deshalb zurück zu den Darstellungsmöglichkeiten. Die ersten PCs von IBM waren dazu gedacht, Texte darzustellen, seien es nun Briefe oder andere Informationen, die sich rein schriftlich darstellen lassen. Bildschirmadapter, die auch Grafik und die sogar in Farbe darstellen konnten, liessen aber nicht lange auf sich warten. Denn schliesslich gab es sogar im Heimbereich schon andere Rechner, die reinen Text nicht nur monochrom sondern auch Farbig darstellten und sogar Grafik anzeigen konnten. Und was Heimanwendern recht war, sollte sich auch für den Bürogebrauch nutzen lassen. Zum Beispiel für CAD, also Computer Aided Design-Anwendungen. So zogen also die Grafikkarten in die (IBM und kompatiblen) PCs ein, die die Bezeichnung auch verdienten. Da aber manche Anwender (noch) keinen Wert auf grafische Darstellungen legten oder meinten, diese nicht zu brauchen, blieben sie bei Monochromkarten und Software, die sich auf Textdarstellung konzentrierte. Auf technischer Ebene spricht man dabei vom sogenannten Textmodus. Wie der Name schon sagt, stellt die Grafikkarte bzw. der Display Adapter in diesem Fall nur Texte dar die zwar mehr oder weniger bunt sein können, es aber nicht sein müssen. Es bleibt aber eine auf Buchstaben und einige wenige grafische Symbole bezogene Darstellung. (Nebenbei: Farbgrafikkarten waren in dieser Zeit, also in der ersten Hälfte der 1980er Jahre auch “saumässig” teuer. So steht in einem Buch über die Programmierung der EGA-Karte von 1987 zu lesen, dass eine solche Karte von IBM mit 256KB Grafikspeicher zu Anfang des Jahres 1986 noch über 2700,- DM kostete.)
Im Gegensatz zum Textmodus steht der Grafikmodus. In diesem Modus, der bei den meisten Benutzeroberflächen heutzutage Standard ist, sind Textdarstellungen auf technischer Ebene auch Grafik. Doch bis sich diese Oberflächen durchsetzen konnten, musste sich die Hardware erst noch weiter entwickeln. Denn die Anforderungen, die eine solche Benutzeroberfläche an die Hardware stellt, sind um vieles höher, als jene, die eine Textoberfläche stellt. Also bleiben wir erst mal bei Programmen, die mit einer Textoberfläche auskommen.
Bevor grafische Benutzeroberlächen aufkamen gab es in der Regel nur einen Zeichensatz und somit auch nur ein Schriftbild, das auf dem Monitor dargestellt wurde. Beim Drucker sah das etwas anders aus, denn der konnte evtl. auch verschiedene Schriften drucken. Es war aber auch möglich, das es sich beim Drucker um eine vom Computer angesteuerte elektrische Schreibmaschiene handelte, womit man wiederum auf eine Schriftart festgelegt war. Wenn ich im folgenden von Druckern schreibe, meine ich aber meisst Nadeldrucker. Das waren (bzw. sind) jene Geräte, deren Druckkopf aus einer Reihe von (stumpfen) “Nadeln” besteht, die übereinander angeordnet sind, gegen ein Farbband hauen und somit Punkte auf’s Papier drucken. In einigen Bereichen werden sie auch heute noch verwendet. In den 80er Jahren waren sie dagegen die Regel, denn Tintenstrahler gab es noch nicht und Laserdrucker waren eher die Ausnahme, weil sie extrem teuer waren. Also zurück zu den Nadeldruckern. Wenn man in ein entsprechendes Gerät investiert hatte, konnte man verschiedene Zeichensätze darstellen. Auch waren diese Drucker irgendwann in der Lage, Fett und Kursiv zu drucken und konnten auch unterstreichen. Das Problem war, dass es keine Druckvorschau gab. Wenn also die Textverarbeitung die Möglichkeit anbot, solche Auszeichnungen zu verwenden, dann konnte man das zwar durch entsprechende Steuercodes im Text einstellen, aber das Ergebnis hat man erst gesehen, wenn das Werk aus dem Drucker kam.
Mit den Textverarbeitungen war es sowieso noch so eine Sache, denn die waren Anfangs noch sehr einfach ausgefallen. Man orientierte sich an der Schreibmaschiene und so wurde es von vielen Leuten anfangs als grosse Innovation betrachtet, dass man einen Text am Rechner nicht nur erstellen konnte, sondern auch in der Lage war, diesen noch zu verändern, ohne eine Seite Papier bedrucken zu müssen. Und weil man sich noch an der Schreibmaschiene orientierte, die eine feste Zeichenbreite hatte, machte man das am Computer erst einmal genauso. Wenn man also das Ende einer Zeile erreicht hatte, oder kurz davor war, hat man einen Zeilenumbruch direkt im Text plaziert. Die Möglichkeit, einfach weiter zu schreiben ohne sich um Zeilenumbrüche kümmern zu müssen, weil dies vom Programm übernommen wurde, war die nächste grössere Innovation, an die ich mich erinnere. Man nennt diese Technik Wordwrapping und ich erinnere mich daran, dass Textverarbeitungen in Testberichten auch danach bewertet wurden, ob sie Wordwrapping beherschten oder nicht. Heutzutage kann das selbst ein einfacher Texteditor wie etwa Notepad von Windows.
Ein anderes Problem war die feste Schriftweite. Bei Zeichensätzen wie
![]()
oder
![]()
ist es so, das alle Zeichen die gleiche Breite haben, genauso wie die oben dargestellten Schriftzeichen aus dem Zeichengenerator der Grafikkarte. Man konnte bei späteren Grafikkarten zwar den Zeichensatz verändern, aber damit liessen sich letztlich nur zusätzliche Zeichen basteln oder bestimmten Codes andere Zeichen zuweisen. An der Breite änderte man damit nichts. Die Zeichen waren nach wie vor alle noch 8 oder 9 Punkte breit. Das änderte sich erst in den späten 80er Jahren, so etwa ab 1988, wenn ich mich recht erinnere. Da konnten die Drucker dann auch Proportionalschrift. – Propo-was?!
Proportionalchrift. Manche Buchstaben, wie etwa das W oder das m sind relativ breit, andere wie das kleine Ell “l” oder das i sind dagegen sehr schmal. Das bedeuted, das sie unterschiedlich viel Platz in der Breite benötigen. Wenn aber alle Buchstaben die selbe Breite haben, wie es im Textmodus oder diesem Satz der Fall ist, dann hat man Lücken im Wort, die das Schriftbild stören oder sonstwie für unschön gehalten werden können.
Diese Probleme hat man bei Proportionalschrift nicht, weil da jedem Buchstabe genau die Breite zugeordnet wird, die er benötigt. Entsprechende Schriften nennt man denn auch Proportionalschriften, denn sie berücksichtigen die Proportionen der einzelnen Buchstaben. Zum Vergleich diese nette Bild aus der Wikipedia:

Hier sieht man sehr schön den Unterschied und nebenbei bekommt man noch mitgeteilt, dass man jene Schriften, die eine einheitliche Zeichenbreite haben, auch als “Monospaced” bezeichnet.
Jetzt hatte man ein Problem, wenn man Texte zwar mit einem Proportionalen Zeichensatz drucken konnte, am Bildschirm aber immer noch im Textmodus arbeitete, wo alle Zeichen monospaced waren. Denn dadurch konnte man am Bildschirm nicht sehen, wie das gedruckte Werk aussehen würde. Nun zeigte aber ein Programm namens Printfox, das 1986 für den C64 erschien, dass sowas sogar auf Heimcomputern möglich war. Printfox kann man schon als richtiges Desktop Publishing Programm bezeichnen, das trotz der begrenzten Hardwareresourcen des C64 vieles erreichte, was PCs (jedenfalls IBM und Kompatible) zu der Zeit noch nicht konnten. Zum Beispiel eine Druckvorschau. Und das Beste an Printfox war, das dieses Programm sogar schon Bilder frei positionierbar im Text einbauen konnte. Man war zwar auf schwarz/weis Bilder beschränkt, bzw. musste sich Graustufenbilder vorher mit anderen Programmen erstellen. Aber da waren die Ansprüche auch noch nicht so hoch, weil die Grafikfähigkeiten des Rechners im Vergleich zu heute auch nicht sehr hoch waren. Die Bildschirmauflösung lag bei 320 x 200 Punkten in 2 Farben oder 160 x 200 Punkten bei 16 Farben. Und Farbdrucker waren auch noch nicht sonderlich weit verbreitet, weil die zu der Zeit erst langsam auf den Markt kamen.
Was die Druckvorschau auf dem PC angeht, so brachten dies einige DOS-Programme in den späten 80er und frühen 90er Jahren auch endlich zustande, sofern der Rechner über eine entsprechende Grafikkarte verfügte. Das Traurige daran ist aus meiner Sicht, das ein Apple Mac oder auch die 16-Bit Heimcomputer Amiga und Atari ST sowas schon längst konnten, sich aber abgesehen vom Mac auf Dauer nicht durchsetzten.
Nach diesem Ausflug in die frühe Welt der Textverarbeitung, wie ich sie in Erinnerung habe, wieder zurück zu den Zeichensätzen. Denn damit kann man auch heute noch Probleme kriegen, wenn da irgendwas nicht richtig eingestellt ist. Nehem wir zum Beispiel die DOS-Codepage 850. Das ist jene Seite, die die Anpassungen des Zeichensatzes für Westeuropa enthält. Darin gibt es so schöne Symbole um Rahmen zu “zeichnen”:
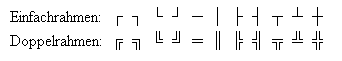
DOS-Rahmensymbole, Eigenes Werk

Bildschirmmaske aus den Rahmensymbolen der DOS-Codepage 850, Eigenes Werk
Der hauptsächliche Zweck dieser Maske besteht darin, möglichst alle Rahmensymbole zu verwenden. Was für ein Programm die verwenden könnte, weis ich auch nicht so wirklich, ist hier aber auch nicht wichtig. Interessant ist eher noch, dass das Bild genau 640 x 400 Pixel gross ist, und damit genau die Grösse hat, die auf einem damals üblichen 14-Zoll Monitor gut darstellbar war. Wenn man diese Maske aber für ein Programm unter Windows übernehmen wollte (was zwar nicht viel Sinn macht, aber darum geht’s ja nicht), dann bekommt man ein Problem, denn dann sehen die Zeichencodes, die unter DOS noch für die Rahmensymbole standen, auf einmal so aus:
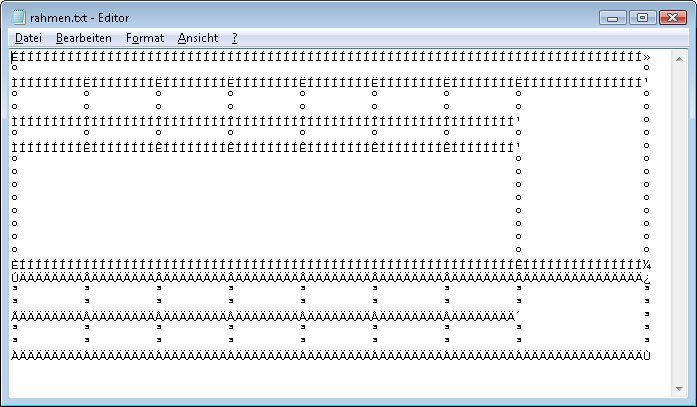
Selbsterstellter Screenshot
Was ist hier passiert? – Nun Windows verwendet einen anderen Code, d.h. den Codes werden andere Zeichen zugeordnet. In diesem Fall nennt er sich Windows-1252. Dabei handelt es sich um eine Microsoft-spezifische Variante von ISO-8859. Das wiederum ist ein 8-Bit Code, der von der Internationalen Organisation für Normung, kurz “ISO” erarbeitet wurde. Man kann also sagen, dass er einen Versuch darstellt, den Wildwuchs von Erweiterungen des ASCII-Codes international zu vereinheitlichen. Die Zuordnungen von 0 (Null) bis 127 entsprechen dabei im wesentlichen dem ASCII-Code, die Zuordnungen von 128 bis 255 werden durch ISO-8859 neu definiert. Da man damit aber nicht alle europäischen Sprachen abdecken kann, gibt es ISO-8859 in 15 “Geschmacksrichtungen“, die durch anhängen von “-X” an die Normbezeichnung gekennzeichnet sind. X ist eine Zahl zwischen 1 und 16 ist, wobei aus irgendeinem Grund die 12 aussenvor bleibt. Deshalb 1 bis 16 und nicht 1 bis 15. Der für Westeuropa definierte Teil nennt sich ISO-8859-1.
Aus einem weiteren Grund, der AFAIK was mit Erleichterungen bei der Softwareentwicklung zu tun hat, hat die ISO den Bereich von 128 bis 159 leer gelassen. D.h. diesen Codes sind keine Zeichen zugeordnet. Und nun wäre Microsoft nicht Microsoft, wenn die das nicht ausgenützt hätten. So haben die bei MS den Bereich von 128 bis 159 mit einigen Zeichen gefüllt, die sie für besonders nützlich hielten und diesen Erweiterungen eigene Nummern zugewiesen. Das sind u.a. die Windows-Codepages 1250 bis 1258, für Westeuropa ist es die Nummer 1252, die auch in Deutschland verwendet wird.
Und wer von diesem ganzen Zahlensalat jetzt reichlich verwirrt ist, dem kann ich leider nicht helfen, denn es geht noch weiter. Da ISO-8859 ein 8-Bit-Code ist, kommt man damit vielleicht in Europa aus, aber eben auch nicht überall. Um nun aber Weltweit Daten austauschen zu können, insbesondere über Netzwerke wie das Internet, hat man schon um 1989 herum angefangen, einen Standard zu erarbeiten, der auf der ganzen Welt benutzt werden kann. Der nennt sich Unicode und war in der ersten Version, die 1991 erschienen ist, 16 Bit breit. Seit Version 2.0 von 1996 ist das gesamte System 21 Bit breit, die man aber kaum alle gleichzeitig brauchen wird. Man sucht sich vielmehr die Sprachen und zugehörigen Schriftsysteme aus, die man braucht und das Betriebssystem sorgt dann dafür, das man damit arbeiten kann. Dabei werden die verwendeten Zeichen innerhalb des Rechners nur mit 16 Bit codiert. Um das zu ermöglichen, gibt es innerhalb des Unicodessystems geeignete Methoden, mit denen sich die benötigten Codebereiche aus dem 21 Bit breiten Bereich innerhalb von 16 Bit darstellen lassen. Wie das im Detail funktioniert, würde diesen Beitrag sprengen, denn das ganze System ist so umfangreich, dass man sich Wochen- oder Monate lang damit befassen kann. Allein die Dokumentation umfasst mehrere hundert Seiten. Dazu kommen noch viele Seiten Anhang, aus denen man die Codes für jedes der 1.114.112 definierten Zeichen entnehmen kann. Wer mehr darüber wissen will, möge sich auf den Webseiten des Unicode-Konsortiums umsehen.
Hier ist in diesem Zusammenhang nur noch das Unicode Transformation Format, kurz UTF interessaant, denn das ist eine der im Internet verwendeten Methoden, Unicode-Zeichen als Bytefolgen darzustellen. Wer sich schon mal intensiver mit Webdesign beschäftigt hat, dem wird das folgende bekannt vorkommen:
<?xml version=”1.0″ encoding=”utf-8″ standalone=”yes”?>
Das ist die Kopfzeile eines XML-Dokuments, also einer Datei deren Inhalt mit der Beschreibungssprache XML beschrieben wird. Der hervorgehobene Teil, encoding=”utf-8″, teilt dem verarbeitenden Programm mit, das der Text mit UTF-8 codiert ist. Das bedeutet, dass die meissten Zeichen 8-Bit breit sind. Wenn die Zeichencodes Werte zwischen Null und 127 haben, sind sie mit dem 7-Bit breiten ASCII-Code identisch. Wenn ein Codebyte mit einem Wert grösser als 127 folgt, ist das ein Kennzeichen dafür, dass das nächste Zeichen durch mehrere Bytes definiert ist, deren Zahlenwert auch jeweils grösser als 128 ist. Dabei sind zwei bis vier Bytes möglich, aber die Details spar ich mir hier. Nur noch soviel: neben UTF-8 sind noch UTF-16 und UTF-32 verbreitet, wobei die Zahl angibt, mit wievielen Bits ein Zeichen kodiert ist. (Technisch interessierte könnte in disem Zusammenhang auch das RFC 4042 gefallen, welches UTF-9 und UTF-18 beschreibt. Zu beachten ist dabei auch das Erscheinungsdatum der Publikation!)
Jetzt noch kurz wieder zur Zeichendarstellung auf dem Bildschirm. Was bei den 16-Bit Heimcomputern (Amiga & Atari ST) seit 1986 normal war, wurde dann ab Windows 3.0 auch auf dem (IBM oder kompatiblen) PC so langsam zur Normalität, nämlich eine grafische Benutzeroberfläche, englisch: Graphical User Interface, kurz GUI. Davon gab es neben Windows 3.x auch noch andere, wovon GEM die bekannteste sein dürfte, gefolgt vom OS/2 Presentation Manager und PC-Geos. Alle diese Oberflächen haben die Gemeinsamkeit, dass sie den PC dauerhaft in den Grafikmodus schalten. Deshalb heissen sie ja auch so. Und wie oben schon erwähnt, sind dadurch auch lesbare Texte im inneren des Rechners nichts anderes als grafische Darstellungen. Das ermöglichte es schliesslich, Software zu entwickeln, die das, was sie auf dem Drucker ausgab, zuvor auch genauso auf dem Bildschirm anzeigte. Im Fall der Textverarbeitung war es damit endlich möglich, einen Text auch so am Bildschirm anzuzeigen, wie er auch aus dem Drucker heraus kommen würde. Auszeichnungen, wie fett, kursiv oder unterstrichen konnten endlich am Bildschirm sichtbar gemacht werden, auch alle miteinander kombiniert. Dazu kam als weiterer Vorteil, dass man auch verschiedene Zeichensätze verwenden konnte, und auch die Schriftgrösse endlich variabel war. Diese ganze Entwicklung lief unter dem Stichwort “WYSIWYG”. Diese Wortschöpfung ist die Abkürzung für What You See Is What You Get, also Was Du (am Bildschirm) siehst, ist das, was Du (aus dem Drucker) heraus bekommst.
Um das zu ermöglichen kam man mit den oben gezeigten “Pixelzeichensätzen” natürlich nicht mehr aus. Wenn man die vergrössert, dann werden die Zeichen irgendwann eckig und/oder Treppenförmig. Das kann man z.B. an den beiden Zeichematrizen des Buchstaben “A” sehr schön sehen, die ich oben zeige. Denn die sind ja sehr stark vergrössert. Um diese Treppenformen zu vermeiden, und einen Bogen bei jeder beliebigen Vergrösserung auch noch wie einen Bogen aussehen zu lassen, hat man sogenannte Vektorzeichensätze eingeführt. Bei diesen Zeichensätzen, werden die Zeichen nicht mehr durch einzelne Punkte definiert, sondern mathematisch durch Kurven beschrieben. Es ist dann Aufgabe der Nutzeroberfläche, ein Zeichen entsprechend einiger Vorgaben auf dem Bildschirm darzustellen. D.h. wenn die Nutzeroberfläche den Code für ein darzustellendes Zeichen bekommt, dann braucht sie weitere Informationen, wie Grösse, Zeichensatz, gewünschte Auszeichnungen, die näher beschreiben, wie das Zeichen dazustellen ist. Aus diesen Informationen berechnet sie dann, welche Pixel der nächsten zu bedruckenden Fläche die gewünschte Schriftfarbe bekommen und welche die Farbe des Hintergrundes behalten.
Soweit mal dieser Ausflung in die Welt der Codierungen und Zeichendarstellungen, ohne die die ganze EDV, die wir hier nutzen, nicht möglich wäre. Auf weitere Entwicklungen bei Textverarbeitungen, die ich ursprünglich vorgesehen hatte, gehe ich nicht mehr näher ein, weil ich zum einen die 20.000 Zeichen Marke schon längst überschritten habe und es zum anderen auch zeitlich nicht mehr hinbekomme. Das Zusammensuchen einiger Informationen und erstellen der oben gezeigten Bilder hat zum Teil mehr Zeit gekostet, als ich erwartet habe.
————————————————-
Screenshot des Infofensters, das erscheint, wenn man in Notepad++ die Erweiterung TextFX installiert hat und daraus die Funktion Wordcount aufruft
————————————————-
Hinweis zum Autor: Dieser Artikel wurde von “Hans” geschrieben.










{kind=link}
{kind=link}
Kommentare (46)