
Einer der diesjährigen “Aufreger” in der Wissenschafts-Blogosphäre war sicher der Verkauf der wissenschaftlichen Literaturverwaltungssoftware und Community-Plattform Mendeley an den niederländischen Elsevier-Verlag im April 2013. Auch hier auf den ScienceBlogs sowie auf den Scilogs wurde dieser Schritt seinerzeit kritisiert, wobei insbesondere die Befürchtung im Raum stand, Elsevier könnte durch die Plattformnutzer hochgeladene PDF-Dateien auswerten und Copyright-Verstöße unterbinden oder sogar deren Abmahnung zulassen. Da wir am An-Institut selbst mit Mendeley arbeiten (wer sich dort mit mir vernetzen möchte, findet hier mein Profil), habe ich diese Diskussion mit Interesse mitverfolgt – und deshalb auch gerne die Möglichkeit genutzt, mit Dr. Victor Henning einen der drei Mendeley-Gründer für die ScienceBlogs befragen zu können. Nachfolgend also Fragen und Antworten ohne weitere Kommentierung. Ein Kurzlebenslauf von Dr. Henning findet sich am Ende des Interviews.
Frage 1: Das Mendeley-Projekt wurde 2008 ins Leben gerufen, das gleichnamige Unternehmen wurde 2009 gegründet. Zu diesem Zeitpunkt gab es bereits eine ganze Reihe etablierter wissenschaftlicher Literaturverwaltungsprogramme, so zum Beispiel EndNote (seit 2000), Zotero und Citavi (beide seit 2006). Woher kam also der Anstoß, ein weiteres Programm zur Literaturverwaltung ins Leben zu rufen?
Dieser Anstoß kam aus den Erfahrungen, die (Mendeley-Mitgründer) Jan (Reichelt) und ich während unsers Studiums an der WHU Koblenz sammeln konnten. Wir haben damals beide mit gängiger Literaturverwaltungssoftware – unter anderem mit EndNote – gearbeitet, welches ich auch für meine Masterarbeit verwendet habe. Gestört hat uns an den bestehenden Lösungen allerdings die Notwendigkeit der aufwändigen manuellen Eingabe von Metadaten zu jedem Paper. Zotero war hier bereits einen Schritt weiter und konnte Metadaten aus über das Internet verfügbaren Veröffentlichungen extrahieren – wer allerdings wie ich bereits über ein umfassendes Offline-Archiv an PDF-Publikationen verfügte, musste sich noch per Hand um die Erfassung der Metadaten kümmern.
Aus dieser Erfahrung heraus entstand die Idee einer Literaturverwaltung, die automatisch so viele Metadaten wie möglich aus den Dokumenten und Online-Dokumentquellen extrahieren und damit zur schnellen Erfassung und Strukturierung bestehender Dokumentenbestände eingesetzt werden kann. Als wir damals Mendeley ins Leben gerufen haben, schwebte uns ein nebenberuflich betriebenes “Freizeitprojekt” vor, da wir beide noch ganz andere berufliche Pläne hatten. Erst eine weitere Idee brachte das Projekt dann auf die heutige Bahn: Wenn Mendeley als Literaturverwaltung weltweit von Wissenschaftlern aller Disziplinen genutzt würde – könnte man dann nicht die dabei entstehenden Daten etwa zum Zugriff auf einzelne Veröffentlichungen oder zur Suche nach Stichworten anonymisiert zusammenführen und auswerten? Ließe sich auf diesem Weg nicht feststellen, wie die Wissenschaftscommunity gerade „tickt“ – also welche Publikationen gelesen werden, welche Themen angesagt sind? Dieser Gedanke hat uns so sehr fasziniert, dass wir uns unbedingt an einer Realisierung versuchen wollten – und 2009 das Unternehmen Mendeley Ltd. ins Leben gerufen haben.
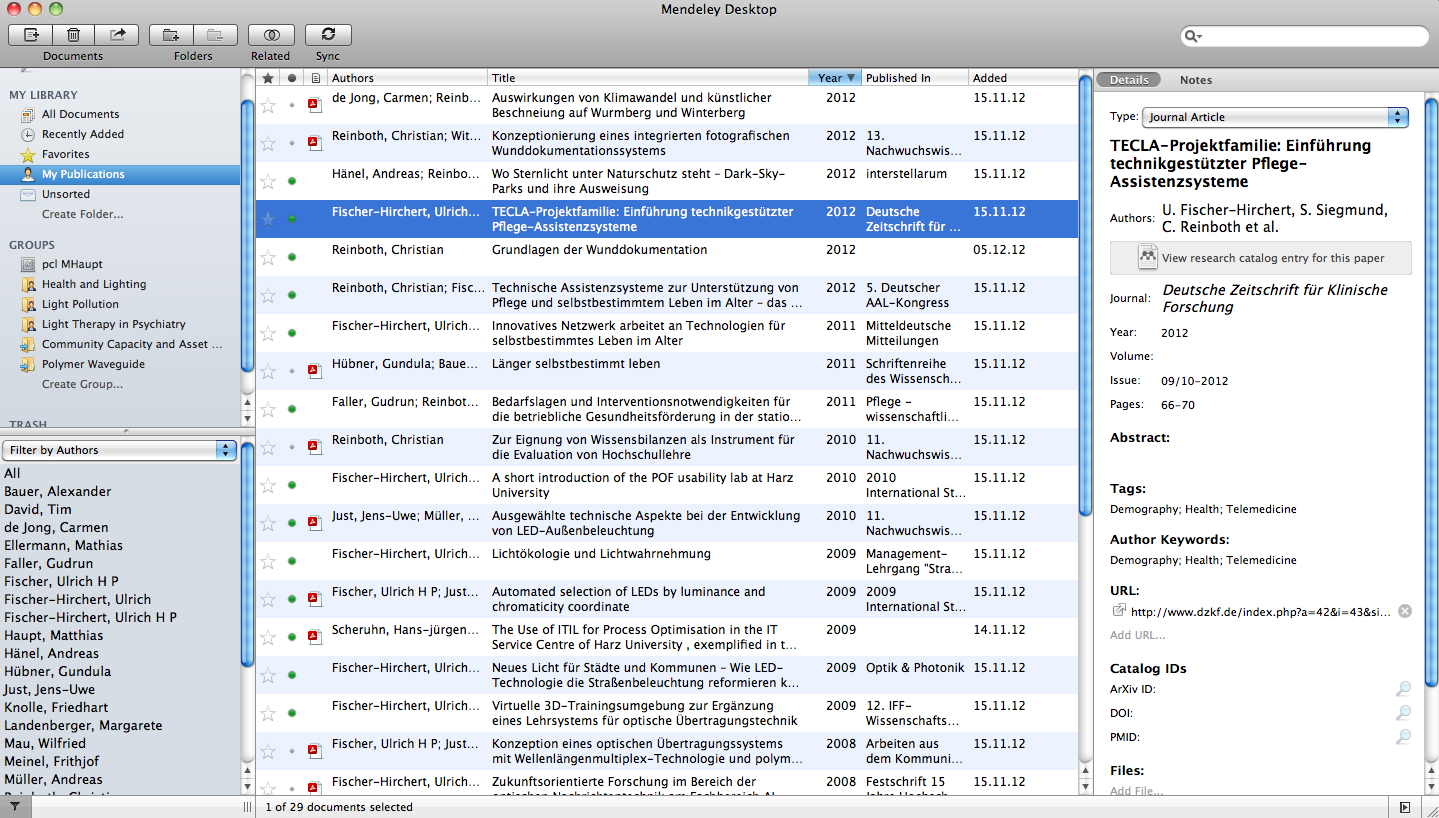
Die Benutzeroberfläche der Mac-Version von Mendeley Desktop.
Nun wurde Mendeley ja nach nur vier Jahren im April dieses Jahres an einen der größten Wissenschaftsverlage – Elsevier – verkauft. Viele Anwender kritisierten diese Verkaufsentscheidung insbesondere vor dem Hintergrund der Befürchtung, dass Elsevier nun zeitnah die PDF-Bibliotheken der Mendeley-Nutzer auf Copyright-Verstöße prüfen könnte und es in der Folge zu einer Welle von Löschungen oder sogar Abmahnungen und Klagen käme. Nun sind entsprechende Berichte seit dem Verkauf ausgeblieben – ist es richtig daraus zu schlussfolgern, dass es zu keinen Löschungen oder Abmahnungen gekommen ist?
Ja, das ist richtig – eine Jagd auf Mendeley-Nutzer wegen Copyright-Verstößen hat es nicht gegeben. Sie ist auch zukünftig nicht zu erwarten. Erstens musste der Elsevier-Verlag uns als Verkäufern als Vorbedingung garantieren, dass keine systematischen Suchen nach Copyright-Verstößen in den Nutzerdaten durchgeführt werden. Und zweitens wäre es ja auch eine extrem schlechte Geschäftspolitik, zuerst eine Community-basierte Literaturverwaltung für viel Geld einzukaufen und anschließend die Nutzer zu verunsichern und die Community zu zerstören. Derartige Befürchtungen werden also auch in Zukunft nicht eintreten.

Kommentare (3)