Die DNA steht im Zentrum des Interesses der Genetik und auch in der Mitte des Namens dieses Blogs. Bei meinen bisherigen Beiträgen setzte ich stillschweigend voraus und verfasste sie daher auch, als sei gegeben, daß die Scienceblog-Leser zumindest in Grundzügen über die DNA bescheid wissen. Da ich damit falsch gelegen haben könnte, hole ich in diesem Basics-Beitrag vorsichtshalber eine Einführung zum coolsten Molekül der Welt nach.
Als Motivation hier erstmal ein Bild von der Schönen:
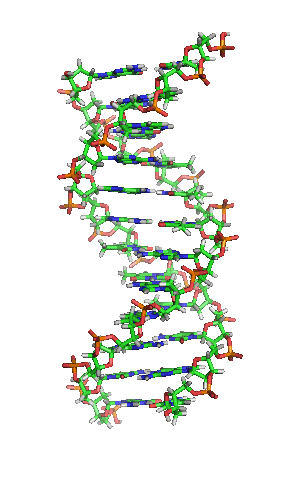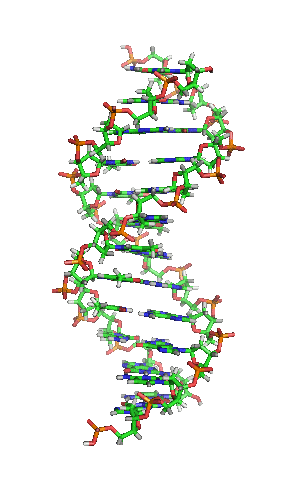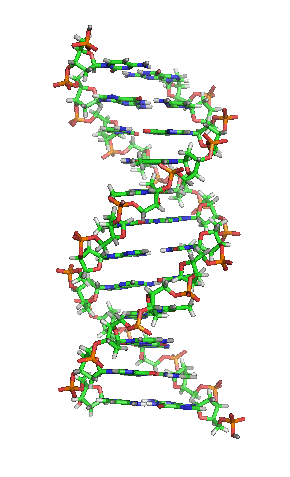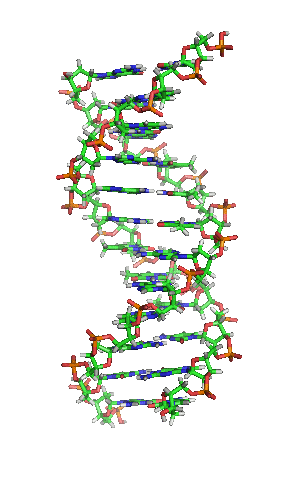
[1]
Die Abkürzung DNA steht für „deoxy ribonucleic acid”, das ist Englisch für „Desoxyribonukleinsäure”, die auf Deutsch mit DNS abgekürzt wird. Aus Gewohnheit, wegen des internationalen Flairs (und weil ich mich über die Franzosen mit ihrer „ADN”-Schrulle aufrege), bleibe ich aber bei der Bezeichnung DNA.
Beginnen wir bei der Etymologie:
Desoxyribo: dieser Wortbestandteil weist auf den Zucker „Desoxyribose” hin, der eine der beiden sich abwechselnden Komponenten im gleichförmig aufgebauten „Rückgrat” der DNA ist.
In der Darstellung sind die Kohlenstoffatome (C) numeriert und Desoxyribose unterscheidet sich von Ribose (dieser Zucker kommt in der RNA vor) darin, daß am zweiten C-Atom keine -OH-Gruppe, wie es z.B. am dritten C-Atom der Fall ist, gebunden ist, sondern nur ein Wasserstoffatom (H).
Nuklein: dieser Wortbestandteil bezieht sich auf das lateinische „Nucleus” (Kern), womit der Kern von Zellen gemeint ist; er weist darauf hin, daß (bei Eukaryoten) die DNA stets im Zellkern aufbewahrt wird.
Säure: der letzte Wortbestandteil zeigt an, daß DNA (A für „Acid” = Säure) eine Säure ist, also ein Molekül, das in wässriger Lösung Protonen, das sind die Kerne von Wasserstoffatomen, abgeben kann. Diese Protonen kommen von der anderen der beiden Komponenten des DNA-Rückgrats, den Phosphationen.
Die Abbildung (links) zeigt ein abgelöstes Phosphation, das seine Protonen schon abgegeben hat und, wenn es in ein DNA-Molekül eingebaut ist, über das rechte Sauerstoffatom („O”) an das fünfte C (C5) eines Desoxyribosemoleküls gebunden ist (s.u.). Diese Phosphationen leiten sich von der Phosphorsäure (H3PO4) ab und können, auch wenn sie in ein DNA-Molekül eingebaut sind, noch ein Proton abgeben, wodurch die DNA insgesamt wie eine Säure wirkt.
Merkwürdigerweise weist der Name der DNA überhaupt nicht auf ihre eigentlich spannendsten, weil nicht alternierend-gleichförmig angeordneten Bestandteile hin: die Stickstoffbasen, die die Basis des genetischen Codes bilden und in deren Anordnung die Information des Lebens niedergelegt ist. In der DNA kommen vier verschiedene dieser Basen vor: zwei Pyrimidin– und zwei Purinbasen. Die Pyrimidinbasen, die in der DNA auftreten, heißen Thymin und Cytosin, die Purinbasen sind Guanin und Adenin.
Die Abbildung zeigt das Adenin-Nukleotid. Es gibt also für jede der vier Basen ein Nukleotid.
Indem seriell jeweils Phosphatanion und Desoxyribose zwischen zwei Nukleotiden verbunden werden und zwar immer so, daß ein Desoxyribosemolekül mit seinen C-Atomen Nr. 5 und 3 an je ein Phosphatanion eines weiteren Nukleotids bindet, entsteht ein Strang aus abwechselnd Zucker und Phosphat, auf dem in regelmäßigen Abständen die Stickstoffbasen „aufgereiht” sind:
Die Abbildung zeigt einen DNA-Einzelstrang, mit der Basenabfolge AGTA (v.o.n.u.). Damit man sich über die Orientierung des Stranges eindeutig unterhalten kann, nennt man das Ende des Stranges, das mit einem 5. C-Atom aufhört (in der Abbildung das obere Ende), das 5′-Ende (gesprochen: „Fünf-Strich-Ende”) und das andere, das mit einem freien 3. C-Atom endet, heißt 3′-Ende.
Bis jetzt ist das alles noch nicht so spannend, zugegeben. Wir haben also einen Strang mit ewig gleichem Phosphat-Zucker-Phosphat-Zucker-Aufbau, einem 5′- und einem 3′-Ende und an jedem Zucker klebt eine von vier Stickstoffbasen. Interessant wird es aber, wenn wir uns daran erinnern, daß die DNA ja eigentlich ein Doppelstrang ist und so die berühmte Struktur der Doppelhelix ausbildet. Es „fehlt” uns also noch ein Strang. Der zweite Strang eines DNA-Moleküls ist strukturell genauso aufgebaut, wie der andere Strang, also mit Phosphat-Zucker-Phosphat-Zucker-Rückgrat, Stickstoffbasen an den Zuckermolekülen, einem 5′- und einem 3′-Ende, aber – und das ist nicht selbstverständlich – damit die Stränge „zusammenpassen”, muß die Basenabfolge des zweiten Strangs anders sein, als die des ersten.
Und jetzt kommt eines der wichtigsten Merkmale der DNA: die beiden Stränge eines DNA-Moleküls sind komplementär, d.h., sie sind nicht gleich, aber sie entsprechen einander: d.h., man kann die Information eines Stranges vollständig aus dem anderen Strang ableiten und umgekehrt (hier habe ich dafür die Englisch/Deutsch-Analogie benutzt). Um einen Doppelstrang bilden zu können, müssen sich die beiden Einzelstränge zusammenlagern. Das funktioniert aber nur, wenn sie so angeordnet sind, daß es „passt”, daß es also keine physikalisch/energetisch ungünstigen elektrostatischen Abstossungen zwischen den Strängen gibt. Der Schlüssel hierfür liegt in den Basenpaarungen, denn von den 4 Stickstoffbasen der DNA kann jede einzelne nur mit genau einer der drei anderen eine stabile also „passende” Paarung eingehen:
Das bedeutet, daß wenn im einen Strang an einer Stelle ein A steht, im anderen Strang an der entsprechenden Stelle ein T stehen muß. Für unseren Beispielstrang oben ergibt sich also für den Gegenstrang die Basenabfolge TCATG (v.o.n.u.). Ein Strang mit dieser Basensequenz würde sich stabil an den AGTAC-Strang anlagern:
Die Abbildung zeigt, wie sich durch Basenpaarung ein Doppelstrang ergibt. Die Basen „paaren” sich aber nicht, indem sie chemisch miteinander reagieren und stabile Verbindungen eingehen, sondern, indem sie sogenannte “Wasserstoffbrücken” bilden (dargestellt durch die gestrichelten Linien), das sind über extrem kurze Entfernungen wirksame elektrostatische Anziehungskräfte zwischen polaren Teilchen, im Fall der DNA zwischen Stickstoff und Wasserstoff bzw. zwischen Sauerstoff und Wasserstoff. Sie sind viel schwächer als „echte” Atombindungen, aber wenn, wie in einem langen DNA-Strang, genug davon gleichzeitig auftreten, reichen sie aus, um die beiden Stränge eines Doppelstranges stabil aneinander zu binden. Diese nicht kovalente Bindung zwischen den Strängen ist sogar so stabil, daß man, um einen langen DNA-Doppelstrang zu trennen (denaturieren), erhebliche thermische Energie (ca. 95°C) aufbringen muß und sie ist energetisch so günstig, daß sich zwei komplementäre Stränge bei nicht denaturierenden Temperaturen „von selbst” richtig aneinanderlagern (das ist auch der Schlüssel für das Funktionieren der PCR, bei der kurze, künstlich hergestellte DNA-Moleküle, die Primer, zum Einsatz kommen).
Man sieht in der Abbildung auch, daß sich zwischen A und T zwei und zwischen G und C drei Wasserstoffbrücken ausbilden, dadurch ist die Bindung zwischen G und C um 50% stärker als die Bindung zwischen A und T. Und noch eine weitere Besonderheit findet sich in der Abbildung: der Gegenstrang eines DNA-Stranges paart sich mit diesem aus stereochemischen Gründen immer in der umgekehrten Orientierung, so daß am Ende eines DNA-Doppelstrangs immer ein 5′- (linker Strang) und ein 3′-Ende (rechter Strang) nebeneinander liegen.
Diese Unterscheidung ist sehr wichtig, weil viele biologische Moleküle DNA- oder allgemein Nukleinsäurestränge nur in eine bestimmte Richtung (meist 5′ -> 3′) ablesen bzw. herstellen können. Ein Beispiel dafür, das ich hier beschrieben habe, ist die DNA-abhängige DNA-Polymerase, die, ausgehend von der Vorlage eines DNA-Einzelstrangs, einen komplementären Gegenstrang nur in 5′->3′-Richtung herstellen kann, wofür sie den Vorlagen-Strang in 3′->5′-Richtung ablesen muß. Bei der Darstellung von DNA-Sequenzen ist es also essentiell, immer die Leserichtung mit anzugeben.
Wir wissen jetzt, wie die DNA aufgebaut ist und wie ihre Einzelstränge zusammenfinden und zusammenhalten, doch wie wird die Erbinformation in der DNA kodiert? Wie bestimmt die Abfolge von Stickstoffbasen die Beschaffenheit eines Genprodukts z.B. eines Proteins? Die Antwort liegt im genetischen Code. Der genetische Code ist ein spannendes Thema für sich und gut für einen eigenen Basics-Beitrag.
Daher an dieser Stelle nur soviel: die Basen, also die Buchstaben der DNA bilden „Worte” (Codons). Jedes dieser Codons besteht immer aus genau drei Buchstaben. Bei vier verschiedenen Buchstaben und drei Buchstaben/Basen pro Wort/Codon in beliebiger Kombination ergeben sich 4 hoch 3 = 64 verschiedene mögliche Wörter. Die allermeisten davon können eindeutig in einen von vielen verschiedenen Proteinbausteinen (Aminosäuren) übersetzt (translatiert) werden: das Codon TTC kodiert beispielsweise für die Aminosäure Phenylalanin. Wenn ein Protein z.B. aus 400 Bausteinen besteht, muß ein Stück DNA, in dem die Information für dieses Protein gespeichert ist, mindestens 400 Codons als 1200 Basen enthalten.
Die letzte Abbildung zeigt zum Abschluß noch die schematische, typische und aus zahlreichen Darstellungen bekannte Form oder Struktur eines DNA-Moleküls: man nennt diese Form Doppelhelix und sie erinnert ein wenig an eine in sich verwundene Wendeltreppe oder Strickleiter. Eine Helix ist eine zylindrisch verlaufende Spiralform. Eine Doppelhelix liegt vor, wenn zwei Helices sich um eine gemeinsame Achse winden. So ist es bei der DNA, die ja meist als Doppelstrang vorliegt: die beiden komplementären Stränge, die aneinandergelagert sich um eine virtuelle Achse winden, bilden eine Doppelhelix.
Die Abbildung weist auch auf die Ausmaße der DNA hin: der Abstand zwischen zwei Basenpaaren beträgt 0,34 nm und eine Windung der Doppelhelix ist 3,4 nm lang.
Für die Aufklärung dieser Struktur im Jahr 1953 erhielten Watson & Crick den Nobelpreis (und verdient hätte ihn genauso sehr Rosalind Franklin), denn erst die Entdeckung der Struktur der DNA ermöglichte es, dieses Molekül zu verstehen und legte den Grundstein der modernen Genetik.
____
Bildquellen:
[1] Zephyris, englischsprachige Wiki; creative commons https://commons.wikimedia.org/wiki/File:DNA_orbit_animated.gif#/media/File:DNA_orbit_animated.gif
![]()

Kommentare (16)