Die DNA steht im Zentrum des Interesses der Genetik und auch in der Mitte des Namens dieses Blogs. Bei meinen bisherigen Beiträgen setzte ich stillschweigend voraus und verfasste sie daher auch, als sei gegeben, daß die Scienceblog-Leser zumindest in Grundzügen über die DNA bescheid wissen. Da ich damit falsch gelegen haben könnte, hole ich in diesem Basics-Beitrag vorsichtshalber eine Einführung zum coolsten Molekül der Welt nach.
Als Motivation hier erstmal ein Bild von der Schönen:
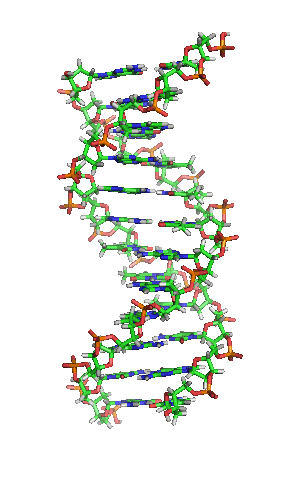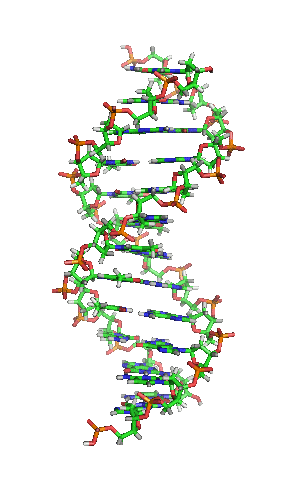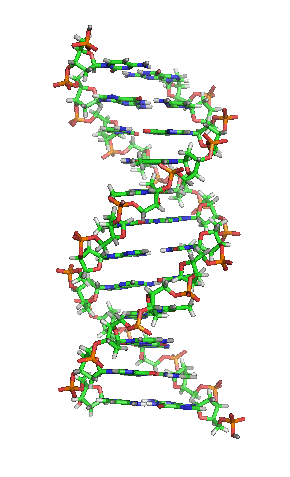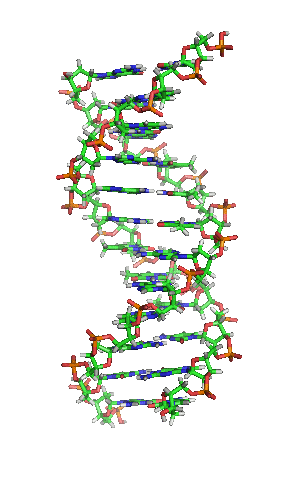
[1]
Die Abkürzung DNA steht für „deoxy ribonucleic acid”, das ist Englisch für „Desoxyribonukleinsäure”, die auf Deutsch mit DNS abgekürzt wird. Aus Gewohnheit, wegen des internationalen Flairs (und weil ich mich über die Franzosen mit ihrer „ADN”-Schrulle aufrege), bleibe ich aber bei der Bezeichnung DNA.
Beginnen wir bei der Etymologie:
Desoxyribo: dieser Wortbestandteil weist auf den Zucker „Desoxyribose” hin, der eine der beiden sich abwechselnden Komponenten im gleichförmig aufgebauten „Rückgrat” der DNA ist.
In der Darstellung sind die Kohlenstoffatome (C) numeriert und Desoxyribose unterscheidet sich von Ribose (dieser Zucker kommt in der RNA vor) darin, daß am zweiten C-Atom keine -OH-Gruppe, wie es z.B. am dritten C-Atom der Fall ist, gebunden ist, sondern nur ein Wasserstoffatom (H).
Nuklein: dieser Wortbestandteil bezieht sich auf das lateinische „Nucleus” (Kern), womit der Kern von Zellen gemeint ist; er weist darauf hin, daß (bei Eukaryoten) die DNA stets im Zellkern aufbewahrt wird.
Säure: der letzte Wortbestandteil zeigt an, daß DNA (A für „Acid” = Säure) eine Säure ist, also ein Molekül, das in wässriger Lösung Protonen, das sind die Kerne von Wasserstoffatomen, abgeben kann. Diese Protonen kommen von der anderen der beiden Komponenten des DNA-Rückgrats, den Phosphationen.
Die Abbildung (links) zeigt ein abgelöstes Phosphation, das seine Protonen schon abgegeben hat und, wenn es in ein DNA-Molekül eingebaut ist, über das rechte Sauerstoffatom („O”) an das fünfte C (C5) eines Desoxyribosemoleküls gebunden ist (s.u.). Diese Phosphationen leiten sich von der Phosphorsäure (H3PO4) ab und können, auch wenn sie in ein DNA-Molekül eingebaut sind, noch ein Proton abgeben, wodurch die DNA insgesamt wie eine Säure wirkt.
Merkwürdigerweise weist der Name der DNA überhaupt nicht auf ihre eigentlich spannendsten, weil nicht alternierend-gleichförmig angeordneten Bestandteile hin: die Stickstoffbasen, die die Basis des genetischen Codes bilden und in deren Anordnung die Information des Lebens niedergelegt ist. In der DNA kommen vier verschiedene dieser Basen vor: zwei Pyrimidin– und zwei Purinbasen. Die Pyrimidinbasen, die in der DNA auftreten, heißen Thymin und Cytosin, die Purinbasen sind Guanin und Adenin.
Die Abbildung zeigt das Adenin-Nukleotid. Es gibt also für jede der vier Basen ein Nukleotid.
Indem seriell jeweils Phosphatanion und Desoxyribose zwischen zwei Nukleotiden verbunden werden und zwar immer so, daß ein Desoxyribosemolekül mit seinen C-Atomen Nr. 5 und 3 an je ein Phosphatanion eines weiteren Nukleotids bindet, entsteht ein Strang aus abwechselnd Zucker und Phosphat, auf dem in regelmäßigen Abständen die Stickstoffbasen „aufgereiht” sind:
Die Abbildung zeigt einen DNA-Einzelstrang, mit der Basenabfolge AGTA (v.o.n.u.). Damit man sich über die Orientierung des Stranges eindeutig unterhalten kann, nennt man das Ende des Stranges, das mit einem 5. C-Atom aufhört (in der Abbildung das obere Ende), das 5′-Ende (gesprochen: „Fünf-Strich-Ende”) und das andere, das mit einem freien 3. C-Atom endet, heißt 3′-Ende.
![]()

Kommentare (16)