

Mehr als 800 Wissenschaftler haben einen Brandbrief gegen die Verwendung des Begriffs „Statistische Signifikanz“ unterschrieben: „Scientists rise up against statistical significance“ (Nature). Worum geht es?
Zunächst: eigentlich geht es nicht gegen statistische Signifikanz, sondern gegen die Verwendung des Begriffes „statistisch nicht signifikant“, sobald irgendwelche Schwellen des p-Wertes überschritten werden.
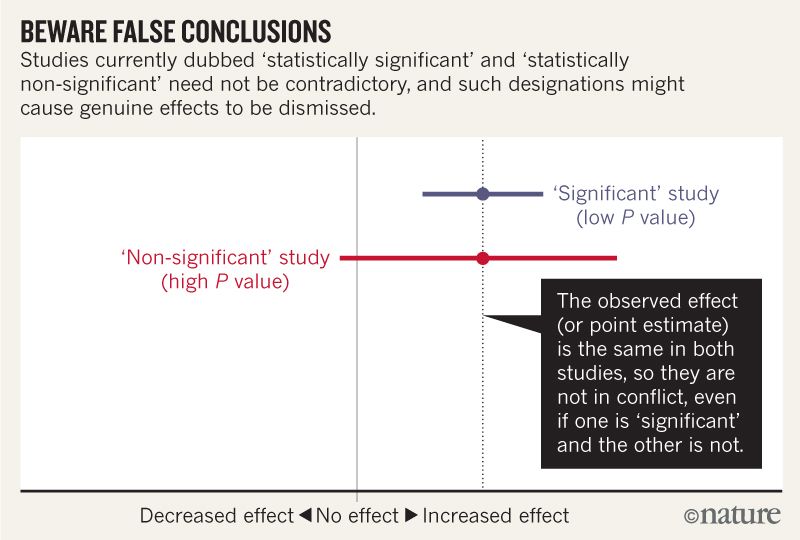
Let’s be clear about what must stop: we should never conclude there is ‘no difference’ or ‘no association’ just because a P value is larger than a threshold such as 0.05 or, equivalently, because a confidence interval includes zero. Neither should we conclude that two studies conflict because one had a statistically significant result and the other did not. These errors waste research efforts and misinform policy decisions.
Die Autoren veranschaulichen das Problem mit dem Beispiel eines Forschungsprojekts zu den Nebenwirkungen entzündundshemmender Medikamente.
Weil ihre Ergebnisse statistisch nicht signifikant waren, kam eine Gruppe von Forschern zu dem Schluss, dass die Medikamentenexposition nicht mit neu auftretendem Vorhofflimmern (der häufigsten Störung des Herzrhythmus) in Verbindung gebracht werden könne und dass die Ergebnisse ihrer Studie im Gegensatz zu den Ergebnissen einer früheren Studie mit statistisch signifikantem Ergebnis stünden.
Die tatsächlichen Daten sind wie folgt. Das Risiko für Vorhofflimmern ist bei den dem Medikament ausgesetzten Patienten um 20% höher gewesen. Die Forscher hatten ein Konfidenzniveau von 95%, worin alles von einem 3% höheren Risiko bis zu einem 48% höheren Risiko enthalten war. Damit kamen sie dann auf einen p-Wert, der über der Schranke 0.05 lag.
Die frühere Studie hatte das selbe um 20% erhöhte Risiko gefunden, sie hatte aber ein Konfidenzintervall von 9% bis 33% angesetzt und hatte einfach nur wegen dieser präziseren Annahme einen sehr viel kleineren p-Wert erhalten.
Die neue Studie zeigte also nichts anderes als die ältere, sie kam nur wegen eines anderen Ansatzes für das Konfidenzintervall zu einem entgegengesetzten Ergebnis bzgl. der statistischen Signifikanz. Das ist offensichtlich absurd.
Kommentare (42)