
Vor kurzem hatten wir hier über Big Data diskutiert. Ein schönes, dazu passendes Buch ist „Die Berechnung der Zukunft“ von Nate Silver.
Nate Silver, amerikanischer Statistiker und Gründer des Prognosen-Blogs FiveThirtyEight, beschreibt darin, so der Untertitel des Buches, „warum die meisten Prognosen falsch sind und manche trotzdem zutreffen“. Dabei geht er auf Beispiele zur Vorhersage von Baseballleistungen, Wahlen, Wetter und Klima, Seuchen und Erdbeben ein. Nate Silver vertritt die Position, dass Big Data ohne gute Theorien nicht sehr erfolgreich sein wird. Auch das ist eine Prognose.
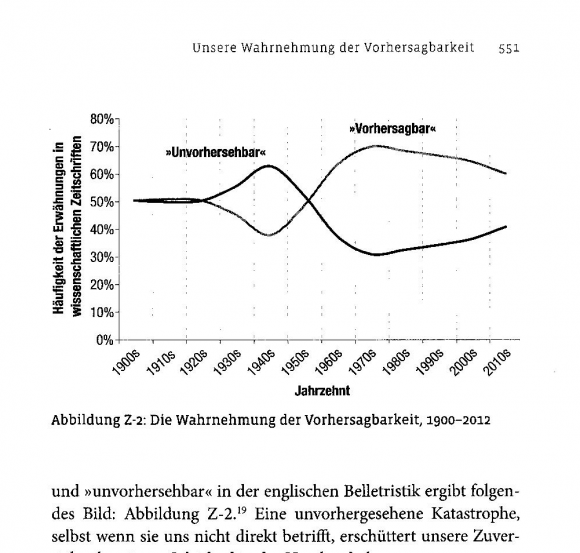
So interessant das Buch ist, etwas ratlos macht mich eine Grafik am Ende des Buches. Sie zeigt Ergebnisse des Google books Ngram Viewers:
.
Es geht, so liest man im Text und in der Beschriftung der Kurven in der Grafik, um die Häufigkeit der Begriffe „vorhersagbar“ und „unvorhersehbar“ in google books. Warum eigentlich „vorhersagbar“, aber „unvorhersehbar“? Im Anhang des Buches ist der Suchalgorithmus für den Ngram Viewer dokumentiert: https://books.google.com/ngrams/graph?content=predictable%2Cunpredictable&year_start=1800
&year_end=2000&corpus=4&smoothing=3.
Demnach wurde also tatsächlich nach „unvorhersagbar“ gesucht. Nun gut, eine sprachliche Petitesse. Schon weniger unwichtig: Im Text ist die Rede davon, wie oft die Begriffe „in der englischen Belletristik“ vorkommen, in der Grafik wird dagegen von der Häufigkeit „in wissenschaftlichen Zeitschriften“ gesprochen. Nicht ganz dasselbe. Und wenn das Auge schon mal auf der Y-Achse ruht, fallen auch die für Ngram-Ergebnisse vergleichsweise hohen Prozentwerte auf. Der Ngram-Link funktioniert noch (man wird weitergeleitet) und führt zu diesem Bild:
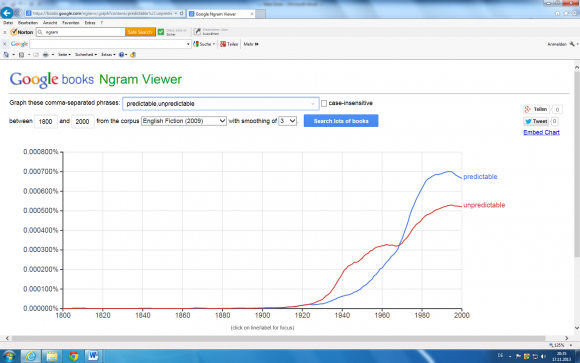
Es zeigt die bei Ngram auch bei Allerweltswörtern üblichen kleinen Prozentwerte. Ein Satzfehler im Buch? Oder habe ich im Kleingedruckten bei Ngram etwas überlesen? Noch seltsamer: Es sind ganz andere Kurven als im Buch. Die 100 ereignislosen Jahre von 1800 bis 1900 hat man im Buch zu Recht weggeschnitten. Woher die Jahre zwischen 2000 und 2010 im Buch kommen, weiß ich nicht, vielleicht eine Extrapolation des Ngram-Trends durch Silver. Aber was ich mich wirklich frage: der Rückgang der Kurven nach den 1920er Jahren („vorhersagbar“) bzw. nach den 1940er Jahren („unvorhersehbar“) – wo ist der geblieben? Diesen Rückgang interpretiert Nate Silver im Buch mit einer historisch einleuchtenden Erklärung, er sollte also auch wirklich existieren. Steht hinter der Grafik im Buch doch ein anderer Suchalgorithmus? Oder kann es sein, dass sich die Ergebnisse zwischen Juni 2013 (lt. Buch wurden da alle Links besucht) und heute so stark verändert haben? Oder gibt es noch andere Möglichkeiten, an die ich nicht gedacht habe?


Kommentare (18)