
Dies ist ja der zweite “Ten simple rules”-Artikel, den ich kommentieren möchte. Geschrieben ist er von einer Gruppe von Leuten aus unterschiedlichen Orten geschrieben, die Eines eint: Sie arbeiten in Bioinformatik Service Projekten oder sogenannten “Core Facilities”. Und somit besteht ihre Tätigkeit – zumindest dem Titel – genau darin zu tun, worum es im Artikel geht.
Bei mir in Mainz gibt es eine Core Facility, wie ich sie mir wünsche, nicht. KollegInnen an der Klinik bieten Unterstützung für Leute aus der Klinik. KollegInnen am IMB, dem molekularbiologischen Institut der Boehringer Ingelheim Stiftung, tun das Ihrige für die WissenschaftlerInnen dort. Und ich versuche das in meinem Gebiet auch – bin allerdings immer wieder mit ganz anderen Dingen beschäftigt, einen Rund-um-Service für Bioinformatik gibt es somit bei uns am Cluster nicht. Und dann gibt es noch Bioinformatikarbeitsgruppen, die teilweise ähnliche Dinge leisten. Was in Mainz einfach fehlt ist eine Core Facility für Bioinformatik wo alle Mainzer WissenschaftlerInnen Zugriff Unterstützung erhalten können – oder zumindest eine Anlaufstelle, die Expertise und Zusammenarbeit vermittelt (also ein “Projekt-Broker”).
Nun aber zum Artikel. Der ist nicht nur mit einem gänzlich anderen Fokus geschrieben als der vorherige, sondern professioneller – wie ich finde. Allein die Regeln 3-7 und 10 drehen sich um Datamanagement! (Also machen wir es kürzer als im letzten Beitrag, schließlich könnt ihr die Artikel auch selber lesen, da ist hier etwas Kondensation erlaubt.):
Interessant ist vor allem auch die Einleitung, die mündet in:
By implementing the following rules, bioinformaticians who routinely provide bioinformatics support to data-generating researchers can work to establish more realistic expectations for analysis while improving the quality and value of outcomes …
Ich finde, genau darauf kommt es an. Also, wie geht es wirklich?
Rule 1: Collaboratively design experiment
Dies ist der professionelle Ausdruck meiner Warnung. Es kommt darauf an, ob man sich schon zusammensetzt bevor das Projekt losgeht und nicht erst nachdem das Projekt-Kind in den Brunnen gefallen ist. Auf einem Hochleistungsrechner (a.k.a. “Cluster”) wollen Bioinformatiker oftmals erst rechnen, wenn sie merken, dass die riesige Kohortenstudie (oder andere Riesenprojekte) auf einem kleinen Server oder Gaming-PC gar nicht zu bearbeiten ist und das eigene Geld für ein paar hundert Server nicht langt. Erst dann aber den Workflow anzupassen oder gar bessere Software einzusetzen ist oftmals eine Herkulesaufgabe: Eigentlich nicht zu bewältigen für alle Nicht-Halbgötter.
Um das zu illustrieren wähle ich üblicherweise dieses Schema:
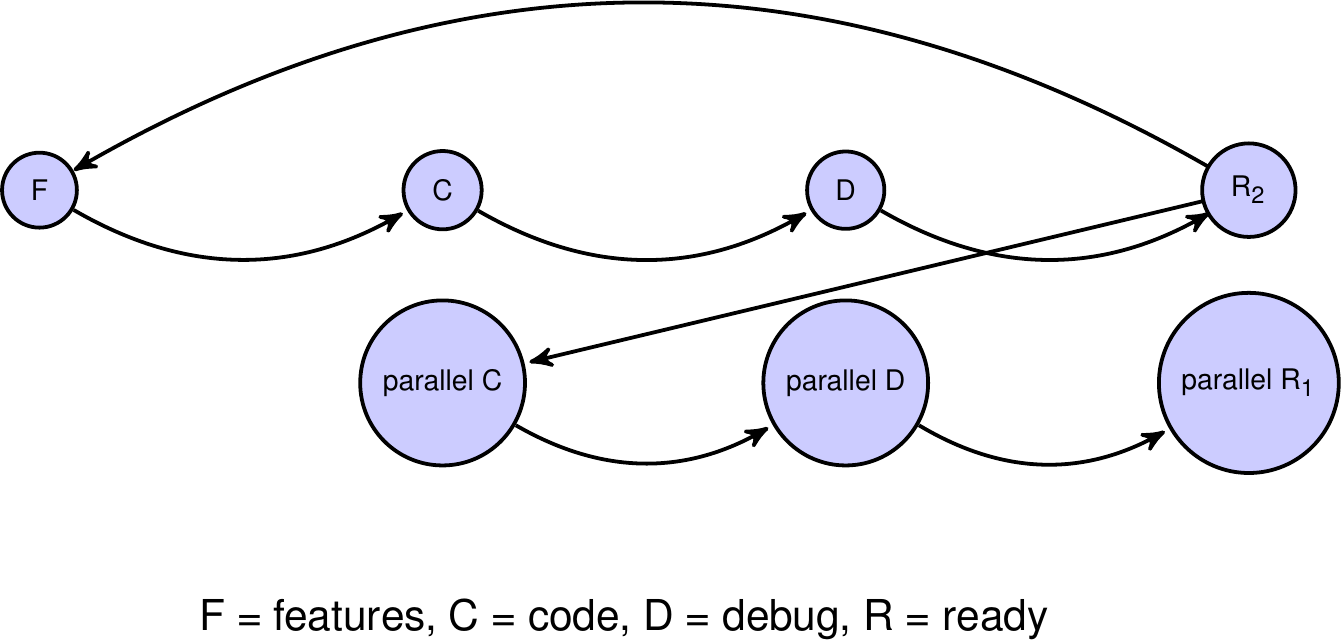
In der Regel wird bei wissenschaftlicher Software – Egal ob Workflow oder Programmentwicklung – eine Liste der gewünschten Eigenschaften (features = F) aufgestellt und ein armes Schwein daran gesetzt diese Vorstellung in Code (C) zu giessen. Dann müssen die Fehler beseitigt werden (debugging = D) und irgendwann erblickt dann diese Software das Licht der Welt (release / ready = R). Dumm nur, dass diese Software zu langsam ist. Also wird arme Sau Nr. 2 daran gesetzt den Code / den Workflow zu parallelisieren (parallel C) und dass muss dann wieder aufwendig von Fehlern befreit werden (parallel D). In der Zwischenzeit schreitet die Wissenschaft voran und neue Eigenschaften werden über die Schritte F->C->D zu einem fortgeschritteneren Stück Software, das von der Gruppe genutzt wird (R2) während die schnellere, parallele Version (R2) zu spät kommt, denn die besseren Ergebnisse lassen sich ja durch die (zwar langsamere) Version R2 erzielen. Das ist der Grund warum ich, bei mir geht es ja um das Rechnen auf Großrechnern, plädiere stets den Weg F->parallel C-> parallel D->parallel R zu gehen: so kann man die großen Datenmengen, vor denen die Zunft Bioinformatik steht besser bewältigen und Enttäuschung über Kollaborationen werden vermieden. (In einer Präsentation poppt das natürlich in der beschriebenen Reihenfolge auf …)
Aber ich will ja etwas dazulernen: Bei klinischen Statisktikabteilungen gibt es häufig einen Vorab-Fragebogen. So etwas habe ich seit einer Weile immerhin für mich – anders geht es nicht, denn Antragsformulare der HPC-Community beziehen sich allein auf technische Aspekte und das ist wenig hilfreich, wenn es um Wissenschaft geht.
Rule 2: Manage scope and expectations
In der Tat, das ist wichtig. Wer früh genug plant und redet, darf auch Hoffnungen auf eine gute Veröffentlichung haben. Andernfalls gilt es diese Hoffnungen eben zu dämpfen: Analyseworkflows für manchen Bedarf hat man im Köcher, manchmal gibt gibt es aber auch neue Anforderungen, da ist es schlecht möglich Lösungen aus dem Hut zu zaubern. Die zu entwickeln oder bestehende Lösungen anzupassen braucht Zeit. Und überhaupt: Auch der beste Analyseworkflow verbessert niemandes Daten. Und damit sind wir wieder beim Thema:
Rule 3-7: Data, data, data
Das ist meine Zusammenfassung der Punkte als Überschrift. Jeder einzelne Punkt ist wichtig, aber für einen Blogartikel darf man alle zusammenfassen:
- Rule 3: Define and ensure data management
- Rule 4: Manage the traceability of data
- Rule 5: Determine how and what metadata are reported
- Rule 6: Coordinate data and internet security
- Rule 7: Control data quality throughout the project lifecycle
Vor ein paar Tagen erst hat ein Arbeitsgruppenleiter mir gegenüber geäußert: “Wegen der DFG muss ich ja meine Daten archivieren.” Ja, in der Tat. Deine Peers haben erkannt, dass es eine gute Idee ist, Daten zu archivieren und vorrätig zu halten. Warum, dass sollte allen klar sein, denen die Skandale der letzten Jahre in den Ohren klingen oder hier mitgelesen haben. Aber leider gilt nach wie vor für viele Verantwortliche: Archivieren und Vergessen, bzw. Archivieren und Löschen ist dasselbe aus Sicht mancher WissenschaftlerInnen, denn “wenn archiviert, muss ich mich nie mehr kümmern!”.
 Es ist ein Trauerspiel: Wir schreiben das Jahr 2020 und müssen immer noch darüber reden, dass Datenmanagement mehr ist als Archivierung?!?? (Ach, ich will gar nicht erst darüber schreiben, dass Backup und Archivierung zwei häufig verwechselte, verschiedene Dinge sind.) Das man einen Plan braucht (den mittlerweile einige Geldgeber, ebenfalls aus gutem Grund, bei Beantragung sehen wollen)? Das alle Daten mit Metadaten versehen werden sollten, die wirklich beschreiben was in den Daten steckt? Und das insbesondere personenbezogene Daten, z. B. genetische Sequenzen, nicht mit dem offenen Arsch im Internet hängen sollen?
Es ist ein Trauerspiel: Wir schreiben das Jahr 2020 und müssen immer noch darüber reden, dass Datenmanagement mehr ist als Archivierung?!?? (Ach, ich will gar nicht erst darüber schreiben, dass Backup und Archivierung zwei häufig verwechselte, verschiedene Dinge sind.) Das man einen Plan braucht (den mittlerweile einige Geldgeber, ebenfalls aus gutem Grund, bei Beantragung sehen wollen)? Das alle Daten mit Metadaten versehen werden sollten, die wirklich beschreiben was in den Daten steckt? Und das insbesondere personenbezogene Daten, z. B. genetische Sequenzen, nicht mit dem offenen Arsch im Internet hängen sollen?
Das alles ist leider immer wieder bitter notwendig. Und daher ist Ten simple rules for providing effective bioinformatics research support ein lesenswerter Artikel für alle, die dieses Geschäft betreiben müssen.
Rule 8: Identify suitable computational tools for data analysis
Auch dieser Punkt klingt irgendwie selbstverständlich. Und doch erinnert noch mein letzter Beitrag (bei Nr. 7) daran, dass Leute auf die absonderlichsten Ideen kommen. Und in bioinformatischen Veröffentlichungen verstecken sich manchmal Skripte, die überhaupt nirgends dokumentiert oder abgrundtief mies geschrieben und lahm sind. Sicher gibt noch weitere Ausschlusskriterien, aber ich möchte nicht verschweigen, dass den Autoren der diskutierten Ten rules eigentlich ein anderer Punkt wichtig ist, den ich ebenso wesentlich finde: Nicht jede Software ist für alle Problemstellungen gleichermaßen geeignet. Beispielsweise wird zum Zusammenstoppeln ganzer Genome Software ausgewählt, die besonders gut mit den zu erwartenden Intronlängen zurecht kommen kann oder bei Bedarf auch mit sog. long reads[Amarasinghe et al., 2020] arbeiten kann. Daneben sind noch andere Aspekte zu berücksichtigen, aber es geht mir um den Punkt, ggf. nicht jeder Überzeugung (vgl. letzter Beitrag, bei Punkt Nr. 1) nachgeben zu sollen – im Interesse guter Wissenschaft.
Rule 9: Track, record, and confirm workflow changes
Erfassen, dokumentieren und validieren von Änderungen eines Vorgehens. Die Überschrift und der Absatz im Artikel erfassen sehr genau, worauf es beim Reproduzierbarkeitsanspruch ankommt: Klar, ebenso wie notwendige Änderungen an einer bestimmten Software erfasst, dokumentiert und überprüft werden soll – was gutes Softwaremanagement ausmacht (Versionsverwaltung, kontinuierliche Integration, etc.) gilt in ähnlicher Form auch für gesamte Workflows. Wenn eine bestimmte Softwarekomponente ausfällt (was bei schlecht gewartet Software passieren kann) oder aus anderen Gründen ersetzt werden muss, gilt es die neue Software zu validieren und die Beweggründe, die zum Ersatz führten zu dokumentieren.
Rule 10: Repurpose the data
Warum sollte man Daten wiederverwenden wollen? Die sind doch publiziert? Mein Verständnis ist, dass durch gutes Datenmanagement dem “repurposing” von Daten für etwaige Metaanalysen oder Kontrollen durch Dritte vorgesorgt wird.
Was die Autoren aber meinen, möchte ich eher mit “Was nichts taugt, kann wenigstens als schlechtes Beispiel dienen” flapsig zusammenfassen: Daten, die fehlerhaft sind, können zumindest dazu dienen Workflows robuster zu machen und auch neue Tests auf Integrität zu implementieren – und sollten entsprechend vermerkt archiviert werden. Ein guter Gedanke! Auf Workflows übertragen, habe ich selber das noch nicht umgesetzt.
Fazit
Ein sehr lesenswerter Artikel für alle, die auf einer Stelle sind, die man mit “Stabsstellen Bioinformatik” zusammenfassen kann. Auch das noch von mir stiefmütterlich behandelte Datenmanagement.
![]()

Letzte Kommentare