
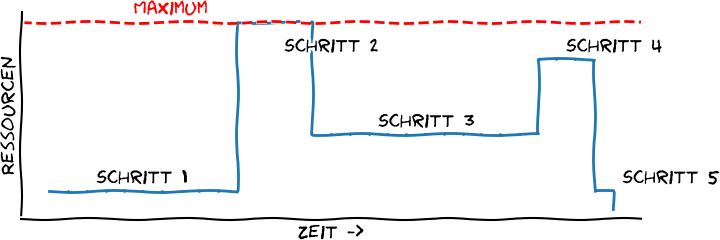
Pipeline oder nicht Pipeline? Im ersten Teil ging es darum zu charakterisieren was eine Pipeline in der Bioinformatik ist. Hoffentlich wurde klar, dass die Weise wie manche Datenanlyse Pipeline umgesetzt wird, extrem verschwenderisch sein kann. Wer erst einmal soweit ist zu erkennen, dass eine gegebene Pipeline heterogene Ressourcenanforderungen hat und das dies ernsthafte Performanceprobleme birgt,…

Was eine Pipeline ist, weiß jeder … In der Bioinformatik ist mit einer Pipeline die Folge von Programmen gemeint, die eine bestimmte Analyse mit mehreren Schritten ermöglichen. Hierbei kann die Pipeline, ganz analog einer “echten” auch verzweigt sein. Sprich: Pipelines entsprechen in Ihrer Abfolge von aufgerufenen Programmen stets gerichteten azyklischen Graphen — in der Regel…
In dieser Woche habe ich ein wenig über die Lehre ab September gesonnen. Werde ich wohl wie im letzten Jahr die etwas umständliche online-Unterrichtsplattform nutzen? Oder, dachte ich während die Sonne mal zwischen den Wolken durchkam, werde ich doch selber wieder einen vollen Kurssaal sehen? Viele Dozenten an den Universitäten kennen gegenwärtig zwei Zustände zugleich:…
Mitten in den rheinlandpfälzischen Herbstferien startet wird in Mainz das Semester wieder beginnen – oder besser: die Vorlesungszeit wieder starten (in anderen Bundesländern sind die Termine andere). Es wird ein ungewöhnliches Semester werden. Eines, in dem die Studierenden mit ihren Träumen und Idealen sitzen werden – meist hinter einem Bildschirm. Kein Brainstorming während oder nach…
Das Publikationswesen in der Informatik ist für mich immer noch seltsam: Konferenzbeiträge, die als reguläre Artikel gelten und keine Zeitschriften die gut indiziert zu durchsuchen sind, wie in den Lebenswissenschaften oder den anderen Naturwissenschaften. Das Denken von Konferenz zu Konferenz, eine Welt in ausschließlich Prototypen und nicht Produktionssoftware oder wissenschaftliche Ergebnisse, wie Naturwissenschaftler sie gewinnen,…
Mit diesem Beitrag möchte ich meine kleine Serie vorläufig beenden. Lehre ist für manche an Hochschulen lästig, für mich aber gehört sie zur Wissenschaft dazu — ich finde sie spannend und so möchte ich auch in Zukunft immer wieder mal Aspekte der Hochschullehre allgemein und für HPC-Anwender im Speziellen zum Thema machen. Zur Sache Zugegeben:…
Im letzten Artikel habe ich beschrieben, dass die Ziele für unsere Kurse insbesondere unsere Ziele sind. Und auch die Inhalte sind unsere (zu einem nicht unwesentlichen Teil: meine) Inhalte. Das ist irgendwie unbefriedigend: Bliebe dies der status quo, muss das Rad ja immer wieder neu erfunden werden — und das in dem Wissen, dass es…
Zur Erinnerung: Als Beispiel für meine Mini-Serie über Lehre dient eine Einsteigerkurs, der das Ziel hat WissenschaftlerInnen, die einen Hochleistungsrechner (auch Cluster) nutzen, die Grundlagen zum selbstständigem Arbeit mit dem Cluster zu vermitteln. Und im ersten Artikel dieser Serie habe ich angedeutet, dass Lehre für HPC-NutzerInnen mit Tücken behaftet ist … Zuerst: Ein Rückblick Ungefähr…
Wo wir schon mal beim Thema Lehre sind: Demnächst (direkt vor Ostern) gibt es bei uns in Mainz einen Kurs, der im jährlichen Wechsel mal in Mainz, mal in Frankfurt von Rolf Rabenseifner (vom HLRS in Stuttgart) durchgeführt wird. Wir wechseln uns bei der Ausrichtung mit unseren hessischen Kollegen ab. Inhaltlich geht es um die…
Wie angekündigt beginne ich eine kleine Serie über Lehre. In den bisherigen Beiträgen fiel bereits die Abkürzung HPC — für Hochleistungsrechnen bzw. High Performance Computing. Als Beispiel soll eine Einführungsveranstaltung zum HPC dienen. Dabei geht es um die Nutzung großer Cluster aus vielen Einzelcomputern, die zusammen mit einem leistungsfähigen Netzwerk und häufig großen Fileservern ein…

Letzte Kommentare