
Container sind in der Welt der IT keine neue Mode. Und so ist es vielleicht nicht verwunderlich, dass ich vor ein paar Wochen einen atemlosen Anruf eines freundlichen Professors erhielt, der mir mitteilte, wir (also meine Institution) bräuchten dringend eine Cloud mit einem bestimmten containerbasierten Workflowsystem. Anders sei reproduzierbare Bioinformatik heutzutage nicht mehr darstellbar! Und…
Wer von euch hat schon mal wissenschaftlich gearbeitet? Eine Diplom-, Bachelor-, Master- oder gar Doktorarbeit? Dann habt ihr auch Datenmanagement betreiben müssen. Die Wahrscheinlichkeit ist groß und sie steigt mit dem Alter eurer Arbeit auf 100 %, dass dieses “Datenmanagement” darin bestand alle Daten auf CD oder (etwas moderner) auf einem Rudel von Festplatten zu…

Alle Software – sofern nicht sehr klein oder sehr lange gepflegt (Jargon: “gut abgehangen”) – enthält Fehler. Immer. Wissenschaftliche Software insbesondere, denn sie ist oft komplex, leider zu oft von Leuten entwickelt, die wenig Ahnung von Softwareentwicklung haben (was zusätzliche Fehlerquellen einführt) und nicht zuletzt wird sie häufig als proof-of-concept entwickelt (sie war also niemals…

Puh, ich weiß, über Excel in der Bioinformatik gab es hier schon einen Beitrag in dieser Serie. Und zuvor auch schon mal in anderem Kontext. Und jetzt, nach einer kleinen Blogpause, noch ein Artikel? Ja, denn im Laborjournal, einer Zeitschrift, die im deutschsprachigen Raum in ziemlich vielen biochemisch arbeitenden Laboren gelesen wird, stand im letzten…
Der erste Versuch war nur halb erfolgreich: Von zwei Stellen wurde eine besetzt. Es geht immer noch um die Anwenderunterstützung in der Biologie für angewandte Bioinformatik. Alles von der Workflowentwicklung bis zum Datenmanagement. Auch nicht genomorientierte Aspekte werden eine Rolle spielen. Hier geht es zur Ausschreibung. Wie beim letzten Mal: Solltet ihr jemanden kennen, den…
Endlich geht es in der der kleinen Serie (1. Teil, 2. Teil) zu schauen, was zu wirklich nachhaltiger Data Science und damit auch Bioinformatik gehört – und warum das so ist. Zunächst aber: Was haben wir vor Augen haben, wenn wir wissenschaftliche Nachhaltigkeit so richtig weit fassen? Wir können Ziele einer idealen Datenanalyse und alles…
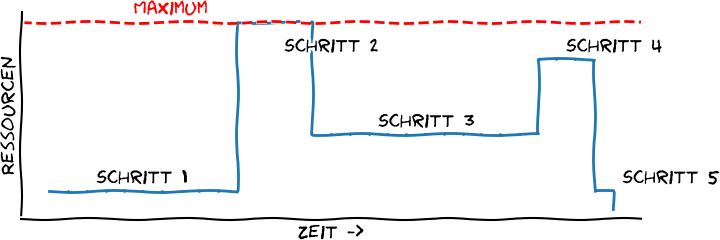
Pipeline oder nicht Pipeline? Im ersten Teil ging es darum zu charakterisieren was eine Pipeline in der Bioinformatik ist. Hoffentlich wurde klar, dass die Weise wie manche Datenanlyse Pipeline umgesetzt wird, extrem verschwenderisch sein kann. Wer erst einmal soweit ist zu erkennen, dass eine gegebene Pipeline heterogene Ressourcenanforderungen hat und das dies ernsthafte Performanceprobleme birgt,…

Was eine Pipeline ist, weiß jeder … In der Bioinformatik ist mit einer Pipeline die Folge von Programmen gemeint, die eine bestimmte Analyse mit mehreren Schritten ermöglichen. Hierbei kann die Pipeline, ganz analog einer “echten” auch verzweigt sein. Sprich: Pipelines entsprechen in Ihrer Abfolge von aufgerufenen Programmen stets gerichteten azyklischen Graphen — in der Regel…
Der Fachbereich Biologie der Universität Mainz schreibt zwei Stellen für die Bioinformatik aus. Es handelt sich hierbei um Stellen zur Unterstützung im Fachbereich, gewissermaßen die Keimzelle einer bioinformatischen Core Facility. Der Alltag wird sehr abwechslungsreich sein und darin bestehen technischen Support zu leisen, HPC-kompatible Workflows mit zu entwickeln und Vieles mehr. Vor allem gilt es…

Letzte Kommentare