
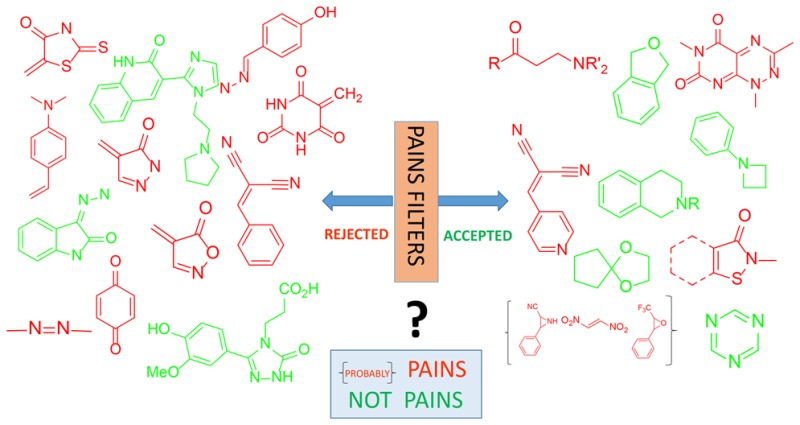
Die Suche nach neuen Wirkstoffen gegen Krankheiten ist eine langwierige, mühsame und teure Angelegenheit. Innovationen gibt es, aber längst nicht in so schneller Folge wie noch vor einigen Jahrzehnten – jedenfalls wenn die moderne Biotechnologie außer Acht gelassen wird und man den Blick auf Wirkstoffe im Sinne einzelner chemischer Moleküle lenkt. Zur Findung neuer Wirkstoffmoleküle…

Ihr ahnt nicht, was es so gibt in der schönen Welt des wissenschaftlichen Rechnens. Viele Programmierer werfen ihren Nutzern einfach so ihre Software vor die Füsse und kümmern sich danach einfach nicht mehr darum. Schließlich funktioniert die fragliche Software ja. Und wer nachfragt, wie man diese ☠@✴#-Software ans Laufen bekommt mitunter zurück: “Bei mir funktioniert…
Zwei Nobelpreise hat sie schon gebracht, die Elektronenmikrospie. Und doch hat sich in den letzten Jahren eine unglaubliche Revolution, die sog. resolution revolution oder Auflösungsrevolution vollzogen. In meiner Diplomarbeit habe ich noch 2D-Elektronenkristallographie gemacht und war froh eine Projektionskarte eines Natrium-Protonen-Austauschproteins (s. o.) von E. coli-Bakterium mit 6 Ångström (1/10 nm, meiner Lieblings-nicht-SI-Einheit mit der…
Dies ist ja der zweite “Ten simple rules”-Artikel, den ich kommentieren möchte. Geschrieben ist er von einer Gruppe von Leuten aus unterschiedlichen Orten geschrieben, die Eines eint: Sie arbeiten in Bioinformatik Service Projekten oder sogenannten “Core Facilities”. Und somit besteht ihre Tätigkeit – zumindest dem Titel – genau darin zu tun, worum es im Artikel…
Ganz zu Anfang des Blogs hatte ich ja schon einmal angedeutet, dass ich einen Zusammenhang sehe zwischen schlechter Software und mangelnder Reproduzierbarkeit von wissenschaftlichen Aussagen. Das es um die Entwicklung von wissenschaftlicher Software, gerade in der Bioinformatik, nicht gut bestellt ist, habe ich ebenfalls behauptet. Und gleich im dritten Beitrag kam die Ten Years Reproducibility…
Kurz nach Start des Blogs erschien in Nature der Aufruf zur “Ten Years Reproducibility Challenge”. Ich habe darüber berichtet und auch zugegeben, dass bei eigener Software nicht immer gut um die Frage nach der Lauffähigkeit nach langer Zeit bestellt ist. Inzwischen gibt es bereits einige Rückläufer in Form von Veröffentlichungen zu einer ausgewählten Software, die…
Lange schon finde ich die Reihe “Ten simple rules for …” des Journals “PLOS COMPUTATIONAL BIOLOGY” amüsant. Ich lese sie gerne und ab und an gibt es Anregung zum Nachdenken – keineswegs sollte man annehmen, dass mit zehn einfachen Regeln ein beliebiges Thema allumfassend behandelt werden kann. Und so ist es auch nicht sinnvoll sich…
Vor einer Weile hat ein Editor einer wissenschaftlichen Zeitschrift beschrieben was ihn umtreibt[Miyakawa, 2020]. Er hat eine besorgniserregende Beobachtung getätigt und – ganz guter Wissenschaftler – die Probe aufs Exempel gemacht, also Daten erhoben und beschrieben: Bei 41 zur Veröffentlichung eingereichten Artikeln war sein Editor-Impuls “This is too beautiful to be true.”. Folgerichtig hat er…
UAP – die “Universal Analysis Pipeline” wurde bereits im letzten Jahr als “Pipeline”-Lösung für Bioinformatik-workflows publiziert[Kämpf et al., 2019]. Für diesen Artikel ist wichtig zu verstehen, dass genomorientierte Bioinformatik (wie auch nahezu alle komplexe Datenanalytik) nahezu jederzeit bedeutet eine Analyse in eine Vielzahl von Schritten (z. B. – Achtung starke Vereinfachung – Qualitätsbestimmung, Qualitätskontrolle, Mapping,…

Letzte Kommentare