
Container sind in der Welt der IT keine neue Mode. Und so ist es vielleicht nicht verwunderlich, dass ich vor ein paar Wochen einen atemlosen Anruf eines freundlichen Professors erhielt, der mir mitteilte, wir (also meine Institution) bräuchten dringend eine Cloud mit einem bestimmten containerbasierten Workflowsystem. Anders sei reproduzierbare Bioinformatik heutzutage nicht mehr darstellbar! Und…

Alle Software – sofern nicht sehr klein oder sehr lange gepflegt (Jargon: “gut abgehangen”) – enthält Fehler. Immer. Wissenschaftliche Software insbesondere, denn sie ist oft komplex, leider zu oft von Leuten entwickelt, die wenig Ahnung von Softwareentwicklung haben (was zusätzliche Fehlerquellen einführt) und nicht zuletzt wird sie häufig als proof-of-concept entwickelt (sie war also niemals…

Puh, ich weiß, über Excel in der Bioinformatik gab es hier schon einen Beitrag in dieser Serie. Und zuvor auch schon mal in anderem Kontext. Und jetzt, nach einer kleinen Blogpause, noch ein Artikel? Ja, denn im Laborjournal, einer Zeitschrift, die im deutschsprachigen Raum in ziemlich vielen biochemisch arbeitenden Laboren gelesen wird, stand im letzten…
Endlich geht es in der der kleinen Serie (1. Teil, 2. Teil) zu schauen, was zu wirklich nachhaltiger Data Science und damit auch Bioinformatik gehört – und warum das so ist. Zunächst aber: Was haben wir vor Augen haben, wenn wir wissenschaftliche Nachhaltigkeit so richtig weit fassen? Wir können Ziele einer idealen Datenanalyse und alles…
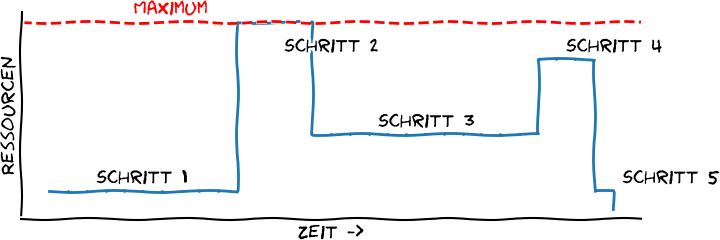
Pipeline oder nicht Pipeline? Im ersten Teil ging es darum zu charakterisieren was eine Pipeline in der Bioinformatik ist. Hoffentlich wurde klar, dass die Weise wie manche Datenanlyse Pipeline umgesetzt wird, extrem verschwenderisch sein kann. Wer erst einmal soweit ist zu erkennen, dass eine gegebene Pipeline heterogene Ressourcenanforderungen hat und das dies ernsthafte Performanceprobleme birgt,…

Was eine Pipeline ist, weiß jeder … In der Bioinformatik ist mit einer Pipeline die Folge von Programmen gemeint, die eine bestimmte Analyse mit mehreren Schritten ermöglichen. Hierbei kann die Pipeline, ganz analog einer “echten” auch verzweigt sein. Sprich: Pipelines entsprechen in Ihrer Abfolge von aufgerufenen Programmen stets gerichteten azyklischen Graphen — in der Regel…
Die Suche nach neuen Wirkstoffen gegen Krankheiten ist eine langwierige, mühsame und teure Angelegenheit. Innovationen gibt es, aber längst nicht in so schneller Folge wie noch vor einigen Jahrzehnten – jedenfalls wenn die moderne Biotechnologie außer Acht gelassen wird und man den Blick auf Wirkstoffe im Sinne einzelner chemischer Moleküle lenkt. Zur Findung neuer Wirkstoffmoleküle…
Ihr ahnt nicht, was es so gibt in der schönen Welt des wissenschaftlichen Rechnens. Viele Programmierer werfen ihren Nutzern einfach so ihre Software vor die Füsse und kümmern sich danach einfach nicht mehr darum. Schließlich funktioniert die fragliche Software ja. Und wer nachfragt, wie man diese ☠@✴#-Software ans Laufen bekommt mitunter zurück: “Bei mir funktioniert…
Wie ich schon vor ein paar Tagen schrieb: Ich unterrichte WissenschaftlerInnen aus nicht-IT-affinen Wissenschaften in Programmierung mit C++ und Python (und shell-Programmierung, etc.). Und das macht Spaß, ich hoffe sehr darauf, dass ich im Spätsommer oder Herbst die Kurse wieder in einem Kursraum mit lauter motivierten TeilnehmerInnen halten kann. Es wird eine große Erleichterung sein,…

Letzte Kommentare