
In der Ausgabe vom 12. Mai schrieb Helen Pearson einen Artikel in Nature unter dem Titel “How COVID broke the evidence pipeline“. Sie kommt sehr schnell auf den Punkt und zeigt, dass mit Ausbruch der COVID-19-Pandemie viele Studien begonnen wurden auf der hektischen Suche nach einem Mittel gegen das Virus und die Spur der Verwüstung, die es in den Körpern der PatientInnen hinterlässt. Viele davon ohne Kontrollgruppen oder gute statistische Grundlangen. Darüber hinaus lassen die meisten Studien die notwendige statistische Power vermissen, ihre Stichprobengrößen sind einfach zu klein, um eine gute Aussagensicherheit zu gewinnen:
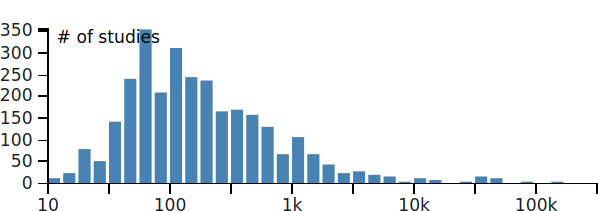
Das war sehr verständlich. Mit Beginn der Pandemie war die Angst groß und es wurde jeder Strohhalm ergriffen, um schnell helfen zu können, auch wissenschaftlich fragliche Schnellschussstudien. Und als wäre das nicht genug, befasst sich eine große Zahl der Studien (allein 250 der Studien in der obigen Abbildung, vielleicht auch mehr) mit Hydroxychloroquin – eine Verschwendung von Mitteln, ohne Frage (wie werden da wohl die Funnelplots aussehen?). Wissenschaftliche Arbeitsgruppen als politische Partisanen? Womöglich.
Wie auch immer, der Bedarf war groß, so auch an systematischen Übersichtsarbeiten. Und selbst diese sind wohl zum großen Teil bereits wieder veraltet, obwohl erst im letzten Jahr erschienen. Es ergibt sich zur Zeit ein “Mosaik der Evidenz” – um den eingangs genannten Artikel zu zitieren – und somit keine gute Grundlage für Entscheidungsträger in Medizin und Politik.
Und so endet der zitierte Artikel und auch ein Kommentar in derselben Ausgabe hoffnungsvoll mit dem Ausblick auf ein Treffen zwischen Vertretern der Cochrane-Organisation (einem Netzwerk zur Förderung der evidenzbasierten Medizin), der Weltgesundheitsorganisation und einer Gruppe namens COVID-END (einem zeitlich limitierten Netzwerk zur Förderung der evidenzbasierten Entscheidungsfindung im COVID-Kontext) im Oktober diesen Jahres, um Lehren aus Problemen in der wissenschaftlichen Begleitung der Pandemie zu finden. Derer gibt es einige, nicht allein im engen wissenschaftlichen Elfenbeinturm, sondern auch in Datenerfassung vieler Staaten, dem transparenten Umgang mit den Daten und der Wichtung, Aufbereitung und Weitergabe von Erkenntnissen.
Insofern ist solch eine anvisierte Verständigung auf globaler Ebene ein wichtiger erster Schritt. Zu Begrüßen wären ähnliche Verständigungstreffen auf europäischer und nationaler Ebene – und reformwillige Akteure.
![]()

Kommentare (26)