

Alle Software – sofern nicht sehr klein oder sehr lange gepflegt (Jargon: “gut abgehangen”) – enthält Fehler. Immer. Wissenschaftliche Software insbesondere, denn sie ist oft komplex, leider zu oft von Leuten entwickelt, die wenig Ahnung von Softwareentwicklung haben (was zusätzliche Fehlerquellen einführt) und nicht zuletzt wird sie häufig als proof-of-concept entwickelt (sie war also niemals zum produktiven Einsatz gedacht).
In dieser Gemengelage wird Software verpackt und anderen Forschenden zur Verfügung gestellt, denn in der Regel installieren diese ihre Software zur Auswertung nicht von “scratch”, also von nicht von Grund auf selber. Man verwendet stattdessen paketierte Software – in der Bioinformatik mittels von Bioconda, auf Hochleistungsrechnern eher mit Hilfe Softwarepaktmanagern wie spack oder easybuild*. Wie auch immer: Jemand packt die Software, jemand installiert diese und – vielleicht die/derselbe – jemand anders nutzt sie.
Es wird also keine große Überraschung sein, auf wen da geschimpft wird, wenn etwas nicht klappt, oder? Immer dann, wenn Moleküle in der Simulation explodieren, das Sequenzanalyseprogramm segfaulted oder man schlicht weiß, dass das Ergebniss falsch sein muss – die Admins oder Paketmanager sind schuld! Schließlich senden wir die Montagsexemplare unseres Konsumgutrauschs ja auch nicht an den Hersteller, sondern an das Unternehmen, welches uns den Kram verkauft hat, oder? Bei wissenschaftlicher Software sind die Paketmanager bloß ganz sicher der falsche Adressat: Sie können nicht für abertausende Pakete mit jeweils abertausenden oder gar Millionen Zeilen von Code die Wartung übernehmen, sondern nur das Paket warten und so garantieren, dass die gewünschte Software irgendwie installiert werden kann.
Wenn ihr also wissenschaftliche Software nutzt und diese gibt eine Fehlermeldung aus oder stürzt sang- und klanglos ab, dann habt ihr zwei Möglichkeiten:
- Ihr schreibt den Administratoren eures Systems / den Paketmanagern / eurer Großtante und hofft, dass irgendjemand euer Problem mit der Software löst.
- Oder ihr schreibt einen sogenannten Bugreport (auch issue report genannt) auf der Entwicklungsseite der fraglichen Software.
Na? Welche Option ist wohl vielversprechender, wenn euch um die Lösung eures Problems gelegen ist?
Was hat das mit der Reproduzierbarkeitskrise zu tun?
Die Antwort auf diese Frage liegt auf der Hand: Fehlerhafte wissenschaftliche Software** kann zu Fehlern in der Auswertung von Daten oder in Simulationen führen. Beseitigte Fehler können Fehlschlüsse in Publikationen vermeiden helfen – Fehlschlüsse, die sonst gar nicht auffallen. Und vor allem können behobene Fehler einem das Leben einfacher machen und im Extremfall den Unterschied machen zwischen einer Publikation, die man schreiben kann, weil Ergebnisse vorliegen, die man anderweitig gar nicht erhalten hätte.
Darüber hinaus wird in der Bioinformatik wahrlich viel Schrott publiziert. Zu oft wird auch einfach nach dem fire-and-forget-Prinzip publiziert – ist das Paper einmal geschrieben, wird sich um die Software nicht mehr gekümmert. Das ist für Anwender selbstverständlich ein Problem: Es steht ja geschrieben, dass die veröffentlichte Software das eigene Datenanalyseproblem zu lösen vermag. Dumm, wenn das nicht der Fall ist. Einen Bugreport zu schreiben, kann die EntwicklerInnen dazu treiben, das beschriebene Problem zu lösen und ihre Software zu verbessern. Gibt es keine Antwort, keine Lösung, ist zumindest für andere Nutzer klar, dass dieses Software-Projekt bereits den Gang in die Vergessenheit angetreten hat – aller Versprechungen im “Paper” zu Trotz. Und das ist für Dritte wertvoll, können diese doch unmittelbar sehen, dass sie sich nach Alternativen umblicken müssen.
Wie geht das – einen Bugreport schreiben?
Ein Teil der Motivation kann somit zwar Frust sein, aber damit nicht noch mehr entsteht, hier ein kurzer Leitfaden zum Schreiben von Bug- oder Issuereports, damit eure Kritik – und das ist ein Bugreport auch immer – produktiv ist:
- Ihr merkt es schon, der Blog, der ziemlich viele Begriffe eindeutscht, besteht hier die ganze Zeit auf “Bugreport” oder gerade eben sogar “issue report”. Das hat einen einfachen Grund: Auch unter Deutschen ist die lingua franca von Technik und Wissenschaft Englisch. Und da sich die Angelegenheit in der wissenschaftlich-technischen Sektion des Internets abspielt: Bitte gutes Englisch.
- Bitte knapp und höflich. — Höflich sollte selbstverständlich sein, ist es leider nicht. Bitte kein Kommandoton und keine Unterstellungen von Fehlerhaftigkeit. Und bitte nicht in epischer Breite erläutern, was der eigenen Ansicht nach schiefläuft, sondern sich das Wesentliche beschränken.
- Das Wesentlich sollte sein: Was habe ich erreichen wollen? Was habe ich versucht? (Achtung: Das sind zwei verschiedene Dinge!) Und natürlich: Was ist passiert? Beziehungsweise: Was habt ihr beobachtet? Und an der Stelle sind dann Logfiles oder Tracebacks (das Zeug, was manche Programme noch ausschreiben, wenn sie röchelnd aufgeben) oder schlicht Fehlermeldungen anzuhängen (und außer bei graphischen Benutzeroberflächen: Bitte keine Screenshots, denn die sind oft lästig, weil man bei wissenschaftliche Software oft nach irgendwelchen Zeichenketten suchen muss und dann als Korrektor peinlich genau abtippen muss. Wie oft habe ich schon nach den Logfiles fragen müssen … Na, jedenfalls: Wenn ihr diesen Punkt richtig macht, spart ihr euch und den Entwicklern Zeit.)
- Jetzt wird es spezifischer: Wenn ihr einen Bugreport zu einer Software angebt, sollten die Entwickler folgende Informationen haben:
- Die Version der Software. Das ist aus verschiedenen Gründen für die Entwickler sehr wichtig: Habt ihr eine ältere Version, kann es sein, dass der Fehler längst behoben wurde oder sich der Code an entscheidender Stelle verändert hat. Ist eure Version aktuell, ist das Problem womöglich noch drängender. (Und die Chance auf schnellere Lösung steigt etwas.)
- Wie wurde die Software installiert? Aus den Quellen oder via Conda, brew, etc.?
- Bitte keine Duplikate. Wenn es euch auf der Githubseite entgegenschreit, dass “euer” Bug schon berichtet wurde, braucht ihr nicht in die Kerbe zu hauen. Und außer in Ubuntuforen ist es auch verpönt ein simples “for me this does not work, too!1!!11!!!” oder ähnlich vielsagende Kommentare zu schreiben. Ihr könnt etwas beitragen? Gut. Sonst wartet einfach, bis der Bug “gefixt” ist oder – wenn das schon länger zu dauern scheint, hakt einfach mal freundlich nach, ob es Fortschritte gibt.
- Manchmal ist es sinnvoll, die Daten zu zeigen, die zu einem Crash führen. Selbstverständlich kann man nun nicht terrabyteweise Daten hochladen – Zeigt die Zeilen, die zum Crash führen und wenn es binäre Daten sind, versucht vielleicht eine kleine Datei zu schreiben, die man doch hochladen kann.
Ach, und nulltens müsst ihr natürlich den Flecken im Internet finden, wo ihr eurer Report loswerden könnt. Wenn die Software eures Vertrauens das nicht anzeigt und die Suchmaschine eures Vertrauens kein eindeutiges Ergebnis liefert, dann habt ihr Pech gehabt. Leider gibt es immer noch Macher wissenschaftlicher Software, die ihren Code nicht rausrücken und zur Diskussion stellen. Und wenn ihr keine Ahnung habt, wie ihr anfangen sollt … normalerweise gibt es schon einige Beiträge in der Bug- oder Issuespalte. Einfach mal reinschnuppern, dann bekommt man schnell eine Ahnung davon, wie die Leute drauf sind und wie man am besten anfangen kann.
Hier noch mal der Vergleich, zwischen einer Software, die ihre Nutzer ernst nimmt und einer Software, die das gar nicht erst versucht:
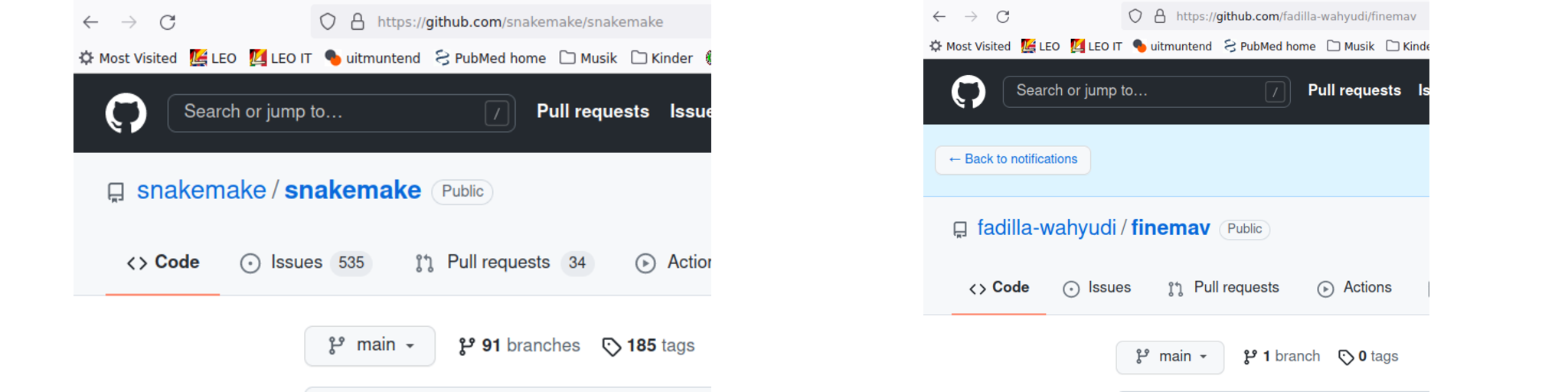
Beispiel für eine aktiv entwickelte Software (links) und ein eben erst entwickeltes Projekt, wo der Autor des Artikels erst mal naiv gefragt hat, wo der Code ist (rechts). Nicht alles “issues” sind bug reports, manche drehen sich um neue Funktionalität oder allgemeine Fragen. Keine oder ungenügende Antworten sind auch ein Indikator für die Qualität wissenschaftlicher Software. Im Falle von snakemake ist die Zahl der “issues” somit vor allem Indikator einer lebendigen “Community”.
Und umgekehrt …
Ok, die Liste oben erhebt keinen Anspruch auf Vollständigkeit – vielleicht fallen euch noch ein paar gute Punkte ein? Her damit! Wir können uns aber auch fragen, was erwarten eigentlich EntwicklerInnen? Und das wurde auch gemacht (dieses Buch, Kapitel 24). Da stehen dann auch so Punkte wie “gute Grammatik ist wichtig” – und das stimmt mit meinem Punkt 1 überein, außerdem kann ich bestätigen, dass manche Bugreports mich absolut ratlos zurücklassen, weil die Grammatik unterirdisch ist (und dabei meine ich nicht allfällige Fehler wie in diesem Blogpost). Ein bisschen Mühe muss halt sein.
Niemand ist “nur” AnwenderIn
Gerade von Bioinformatik-AnwenderInnen höre ich immer wieder*** ein “Aber, ich habe ja keine Ahnung …” mit Bezug auf IT-Dinge. Das ist selbstverständlich Unsinn. Wer wissenschaftliche Software anzuwenden versteht, hat bereits einen Fuß in der IT-Welt. Ebenso wie Wissenschaft von der Gemeinschaft aller Forschenden profitiert und man sich (im Idealfall) wissenschaftlich-technische Hilfestellung gibt, kann man auch in IT-Dingen der Gemeinschaft was zurückgeben und den EntwicklerInnen wissenschaftlicher Software Feedback geben. Für wen das nicht Grund genug ist: Wenn ihr wegen eines Softwarefehlers in eurer Arbeit nicht mehr weiter wisst, ist es spätestens aus Eigeninteresse Zeit und Grund tätig zu werden und einen Bugreport zu schreiben.
+++
- Der Unterschied liegt a) in der Performance – weil Conda installierte Software nicht optimal kompiliert wird, sondern auf jedem System laufen soll und b) darin, dass Cona-Paketmanager so ziemlich jede Software unabhängig von Lizenzfragen und ähnlichen Kinkerlitzchen bereitstellen.
** Wie immer geht es um wissenschaftliche Software. Bei der Bürosoftware eurer Firma habt ihr womöglich andere Bedingungen (z. B. eine Telefonnummer, wo der Softwarekummer abzuladen ist).
*** direkt oder Hörensagen
![]()

Kommentare (27)