

Zusammen mit Kollegen an anderen Einrichtungen bemerke ich immer wieder, dass nicht-IT-affine Universitätsarbeitsgruppen für bestimmte Projekte eine(n) BioinformatikerIn zu einer Masterarbeit oder Doktorat “anheuern”. Heraus kommt eine Software …
Damit das hier ein konstruktiver Beitrag wird, brauchen wir ein Beispiel. Am besten ein schlechtes Beispiel, denn damit werden bestimmte Fehler augenfällig. Nehmen wir: Mich. Kleine Skripte spielten eigentlich bei allen meinen Veröffentlichungen eine Rolle, aber meine erste “größere” Softwareveröffentlichung entstand in einer Gruppe, deren Hauptthema Biophysik war[Meesters et al., 2012] – leider hinter einer Paywall, aber wer diesen Artikel liest, will die Software sowieso nicht verwenden. Und ob sie heute noch laufen würde? Wohl nur bei mir und mit viel Gefrickel. Damit enthält sie die Zutaten, um die es hier geht:
- WissenschaftlerInnen in Ausbildung (DoktorandIn oder MasterstudenIn) ohne IT-Hintergrund (damals konnte ich schon ganz gut in Python und C++ programmieren, aber habe keine formelle Ausbildung in der Informatik) programmiert eine Software innerhalb
- einer nicht-IT-affinen Arbeitsgruppe (in meinem Fall eine Biophysik-AG)
- ohne Betreuung zum Software-Teil der Arbeit.
Da können einige Fehler gemacht werden, die Anwendern einer hoffentlich publizierten Software die Arbeit schwer machen und die aufbauende Wissenschaft schwer machen – im besten Fall durch Unauffindbarkeit der hochgelobten Software. Vor allem aber schaden sich die ProgrammiererInnen zum Teil selbst und ihrer Karriere.
Was können also GruppenleiterInnen und StudentInnen aus meinen Fehlern lernen?
Betreuung
Versetzt Euch mal in folgende Situation — viele hier kennen Sie aus eigener Anschauung, dürfte also den meisten leicht fallen: Ihr habt gerade das Studium abgeschlossen und sucht ein Thema für die Abschlussarbeit oder habt diese hinter Euch und wollt eine Dissertation versuchen. Es braucht eine AG, die Euch aufnehmen will (und Stellen bieten kann). Das sollte sie bieten:
- nette Leute
- ein interessantes Thema
- gute Betreuung
Vielleicht fallen Euch noch mehr wichtige Aspekte ein, aber wir wollen uns mal nicht in Details verlieren … Ob in der möglichen Arbeitsgruppe eine gute Stimmung herrscht ist extrem wichtig! Im Idealfall lässt man Euch unbeaufsichtigt durch die/den LeiterIn mit den Mitgliedern der Gruppe reden. Wenn nicht, dann sollten wenigsten einige aus der Gruppe bei Eurer Vorstellung dabei sein. Andernfalls oder wenn die Stimmung eher durch Vorsicht geprägt ist, sollten die Alarmglocken schrillen.
Um zu testen, ob ein Thema interessant ist empfehlen Francis Crick und ich den “Laber-Test”: Hört Euch ein wenig über das Thema an, lest ein wenig darüber – und vor allem sprecht darüber. Nach dem nächsten Kneipenabend oder einem netten Plausch mit Eurer/m PartnerIn oder Freunden merkt jeder, ob das Thema wirklich anziehend ist. Rede ich darüber gerne? Möchte ich noch mehr wissen? Mich wirklich reinhängen?
Bleibt der Punkt der guten Betreuung. Wenn die/der LeiterIn keine toxische Persönlichkeit hat (was wir hoffentlich durch die gute Stimmung in der Arbeitsgruppe ausschließen konnten), sollte die Arbeitsgruppe im fraglichen Feld erfolgreich sein – schließlich will man ja publizieren und sich die wissenschaftliche Karriere offen halten. Wenn jedoch die Konstellation “Arbeitsgruppe ist für mich fachfremd” auftritt (zunächst einmal ganz allgemein), dann sollte das Thema Betreuung durch (räumlich nahe?) Kollaborationspartner angesprochen werden: “Denn wenn Du, liebe(r) LeiterIn, meine Arbeit niemals in Gänze nachvollziehen können wirst, woher weiß ich dann, ob ich richtig denke und mich nicht vergaloppiere? Mit wem – aus meinem Gebiet – kann ich mich sonst austauschen? Schließlich wollen wir ja Jahre zusammen verbringen und Du möchtest mich, die/der ich für Dich fachfremd bin, um weiter zukommen.” In Zeiten interdisziplinärer Projekte haben die Universitäten einen Strauss von Maßnahmen zur Milderung dieses Problems ausgedacht: Von angepassten Promotionsordnungen über enge Kollaboration zwischen Einzelgruppen bis zu Graduiertenschulen.
Dennoch wird die gerade angesprochene Frage nicht immer gut beantwortet. Und auch dann sollten die Alarmglocken schrillen: Die Leute sind nett, das Thema interessant, aber am Ende des Tages möchte ich mich irgendwo bewerben können. Und wie gut die eigenen Chancen stehen hängt auch vom Erfolg der Abschlussarbeit oder der Promotion ab. — Vor allem aber soll eine Abschlussarbeit auch dazu dienen, dass Ihr etwas dazulernen könnt – und das geht ohne gute Betreuung nicht.
Letztlich ist gute Betreuung ein weites Feld wozu viel geschrieben wurde – wesentlich für die Fortführung dieses Artikel ist ja nur der dritte Aspekt: Wenn eine AG jemanden aus einer anderen Disziplin ins Boot holen möchte, dann muss auch für externe Betreuung oder Mit-Betreuung gesorgt sein. Andernfalls drohen diverse zusätzliche Fallstricke. Mein Doktorvater hat bis zum Schluss immer wieder vollkommen unrealistische Ideen gehabt, die man auch mit der Software lösen sollte – ist ja im Computer, also einfach … der Konflikt zwischen Erwartung und Wirklichkeit ist also einer dieser Fallstricke.
Struktur der Software
Jetzt werden wir etwas spezifischer und kommen mehr Richtung Bioinformatik: Viele Anfänger machen den Fehler und legen los ohne zu planen. Planung sollte zumindest umfassen mit Anderen zu reden und einen Plan auf Papier zu machen. Gutes Software Engineering geht weiter, aber das ist ein Thema für sich. Ich habe damals geplant und mich sogar vom IceCube-Projekt inspirieren lassen! Die hatten damals (wie es heute ist, weiß ich nur ungefähr) so ein tolles Schichtmodell von Python als Scriptinterface für C++-Routinen (die es gibt, weil die Python-Implementierung zu langsam wäre). Hat mich sehr überzeugt und weil ich glaubte ein ähnlich Problem zu haben, habe ich etwas Mimikry betrieben:
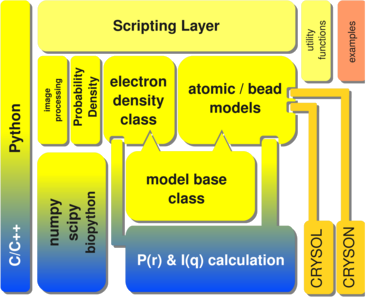
Die Implementationstruktur meiner damaligen Software. ‘Crysol’ und ‘Cryson’ sind Programme des DESY für Röntgen- bzw. Neutronstreudaten. Abbildung aus meiner Veröffentlichung mit Genehmigung von Elsevier (s. u.)
Ich habe also ein paar Routinen in C bzw. C++ ausgelagert, um ausreichende Geschwindigkeit zu erzielen, toll! Eine saublöde Entscheidung, weil
- die Software so schwer zu installieren wurde – und Software, die schwer zu installieren ist, muss anderweitig überzeugen, sonst wird sie nicht genutzt
- die Software so schwer zu nutzen wurde: Fällt euch der “Scripting Layer” auf? Das heißt ich hatte die naive Erwartung, dass Nutzer sich selber Skripte schreiben – während der Arbeit habe ich gelernt, dass selbst in dieser recht mathematikaffinen Umgebung des biophysikalischen Institutes die Zahl derjenigen die aktiv und willentlich Skripten auf ca. 4 von 12 belief (Studis, die gerade Praktikum machten nicht mitgezählt) und einer davon wir ich! Die Betonung liegt auf willentlich: Wenn die Softwarewelt keine Alternative (z. B. ein Programm mit graphischer Benutzeroberfläche oder eine einfach zu parameterisierendes Kommandozeilenprogramm) bietet, dann wird doch gescriptet.
Mein potentieller Nutzerkreis bestand somit aus der Schnittmenge derjenigen, die Kleinwinkelstreuung an großen Proteinkomplexen betrieben und denjenigen, die Konformationswechsel mit dieser Technologie mittels rigid-body-modeling nachvollziehen wollten. Das war die Grube für das Grab dieser Software.
Ein anderer Fehler, den Anfänger häufig machen: Einfaches Programmieren durch Hineinflantschen von Bibliotheken oder dem Mischen zu vieler Programmiersprachen.
Um das Verwenden von Bibliotheken kommt man nicht nur nicht herum – es ist sogar unabdingbar für die Produktivität. Schließlich ist niemandem zuzumuten die 7518te Implementierung von Algorithmus X zu schreiben, für den es in allen gängigen Programmiersprachen mindestens eine optimierte Implementierung gibt. Und so spricht nichts dagegen Bibliotheken zu verwenden, die für die gewählte Programmiersprache etabliert sind und eine große Community haben. Aber danach sollte man schon schauen.
Und was die zu vielen Programmiersprachen anbelangt, habe ich wenigstens diesen Fehler hier nicht nicht gemacht: 2-3 die sich gut Verbinden lassen sind kein Beinbruch. Trotzdem sollte man erkennen, dass Projekte mit 5 verschiedenen Sprachen plus fixe hadoop-Versionen direkt in die neunte Wartbarkeitshölle führen[Brinkmann et al., 2017] – in diesem Fall darf man auch von einer Co-Autorschaft Abstand nehmen, was ich hier getan habe.
Code-Eigenheiten
Also wird ein schöner Algorithmus geschrieben. In meinem Fall eine Variation des Monte-Carlo-Modells. Da es hier um sogenanntes rigid-body-modeling ging, gehörte dazu das Drehen von Untereinheiten wirklich großer Proteinkomplexe – im Zweifel Millionen von Atomen (ohne Wasserstoffe) in jedem Schritt. Dazu habe ich in meiner Naivität sogenannte Rotationsmatrices gewählt, die auf eine Menge von Atomen gemäß der unterliegenden Symmetrie des jeweiligen Komplexes angewendet wurde. Extrem lahm in Python. Also habe ich das in C++ übersetzt und eingebunden und damit von geschätzten >10 Jahren auf eine Woche eingedampft (mit Parallelisierung). Oh, was war ich toll!
Oh was war das doof: Wenn ich gute Betreuung gehabt hätte, wäre die naheliegende Frage im Gruppentreffen gewesen: “Sag’, warum nimmst Du nicht Quaternionen?” Tja, warum nicht? Damit wäre die Simulation wohl noch wesentlich flotter und vor allem einfacher zu implementieren gewesen … Aber manchmal sieht man den Wald vor Bäumen nicht …
Alleine Programmieren
Damit sind wir nochmals bei der Ursache des fehlenden Korrektivs: Der fehlenden Betreuung. Beziehungsweise den fehlenden Kollegen. Wenn diese nämlich im Labor schwärmen und lärmen und visieren wie Falken, wer soll dann darauf hinweisen, dass man sich vergallopiert? Großen Projekten sieht man das kollaborative Arbeiten und gegenseitige Korrigieren mitunter an (Beispiel). Ein Gegenbeispiel stammt aus meiner Nachbarschaft[Kadlec et al; 2017] – der Code ist nicht veröffentlicht und enthält Dinge wie mehrmaliges (unnötiges) Kopieren großer Datenstrukturen, statt simpler Übergabe und manueller Schritte, die man auch automatisieren hätte können.
Versionierung
Darüber im Jahr 2020 noch schreiben zu müssen ist traurig. Doch aus meiner Beratungstätigkeit weiß ich, dass auch heute noch dieser Softwareentwicklungskardinalfehler begangen wird: Keine Versionierung!
- ohne Versionierung keine Protokollierung – die ist im Sinne beider Rollen: Von StudentIn und BetreuerIn. Denn ohne Protokollierung kein Nachweis der Arbeit. Softwareentwicklung hat wie die Arbeit der Laborratten ihre Längen. Die Laborleute haben ihre Laborbücher und können zeigen: “Ich habe letzte Woche 5 Gele laufen lassen! Schau hier!” Wer programmiert kann sagen: “Ich habe letzte Woche 10.000 Zeilen mit einer Coverage von 83 % gecoded für die ich auch noch die Tests geschrieben habe! Schau hier!” – sofern darüber Protokoll geführt wurde – am Besten mit Versionssystem.
- Wer arbeitet macht Fehler. Wenn ein Stück Software eine gewisse Größe erreicht hat und dieses Stück keiner Versionsverwaltung unterliegt, passiert früher oder später Folgendes: Man arbeitet vor sich hin und irgendwann testet man … Shiet funktioniert nicht mehr! Wo ist jetzt der Fehler? Mit Versionsverwaltung kann man jetzt zumindest systematisch suchen.
Zum Thema Softwareversionierung liesse sich noch vieeel mehr aufzählen und rund um Softwareversionierung ebenso (Beispiel), aber dieser Artikel ist schon lang genug. Punkt ist, darauf zu verzichten wird in einer professionellen Umgebung nicht passieren.
Darüber hinaus gibt es noch einen ganz wichtigen Punkt der dazu gehört: Releases. Schließlich will das gute Stück am Ende publiziert werden und zwar nicht nur als wissenschaftliches “Paper”, sondern auch die Software selber. Versionsverwaltungsplattformen ermöglichen das Hochladen einer Version des Projektes – und den möglichen Nutzern den Download.
Wenigstens das habe damals ich nicht versemmelt …
Hosting
Damals habe ich meine Software auf “origo” veröffentlicht. Dazu gibt es zwar eine Veröffentlichung[Bay et al., 2012]. Das war wirklich eine tolle Plattform. Jedoch weiß ich heute, dass proof-of-concept-Arbeiten von Informatikern wirklich toll sein können, manchmal auch so aussehen, aber absolut ungeeignet sind für den Produktionseinsatz. Meine Software habe ich 2008/2009 geschrieben. Die Hostingplattformen (die z. T. nach einer Versionierungsverwaltung benannt sind) Github und Bitbucket erschienen 2008. Was am Ende langfristig trägt kann keiner vorhersagen (Bitbuckets Nutzerzahlen sinken, Github wurde von Mikrosoft übernommen, was auch manche Nutzer zur Abkehr bewogen hat), vielleicht bietet Eure Institution auch einen derartigen Service? Staatliche Institutionen haben ja manchmal einen langen Atem – für Rheinland-Pfalz hosten meinen Kollegen z. B. gitlab (direkt nur zugänglich mit Account einer Hochschule in RLP)
Wie auch immer: Irgendwie muss der eigene Code im Zusammenhang der Veröffentlichung als wissenschaftlicher Aufsatz ebenfalls veröffentlicht werden. Also muss da eine Wahl getroffen werden. Wie der letzte Beitrag in dieser Serie zeigt: Selbst das ist nicht immer garantiert.
Fazit
Wenn ihr also gerade dabei seit Euer Studium abzuschließen (z. B. in der Bioinformatik) und Euch reizt eine Arbeitsgruppe, die keine Expertise in eurem Gebiet hat (wahrscheinlich weil diese Arbeitsgruppe jemanden wie Dich sucht und eine Stelle anbietet), dann seit vorsichtig: Ich wisst schon sehr viel, habt Euch durch ein hartes Studium gekämpft – aber direkt als EinzelkämpferIn durchstarten? Ist es das was Ihr wollt und Euch zutraut? Jede einzelne Hürde dieses Artikels kann genommen werden. Im Studium habt Ihr alles schon gehört. Und dennoch gibt es zu Hauf Veröffentlichungen, die deutlich zeigen, dass diese essentiellen Aspekte nicht immer berücksichtigt werden (ein Vorgeschmack).
+++++++++
Wiedergabe der Abbildungen konnte dank Elsevier erfolgen. Folgende Fußnote muss ich angeben:
Reprinted from “Computational Biology and Chemistry”, Volume 24 / Issue 3, Author(s), “Monte Carlo-based rigid body modelling of large protein complexes against small angle scattering data”, Pages No., Copyright (Year), with permission from Elsevier [OR APPLICABLE SOCIETY COPYRIGHT OWNER].” Also Lancet special credit – “Reprinted from The Lancet, Vol. number, Author(s), Title of article, Pages 158-164., Copyright (2012), with permission from Elsevier.”
![]()

Kommentare (9)