
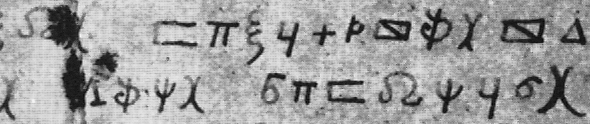
In einem Buch über Kryptologie-Geschichte aus den Siebzigern ist die verschlüsselte Nachricht eines “gefährlichen Codeknackers” abgebildet – leider ohne Lösung.
Das Buch Codes and Ciphers von Peter Way aus dem Jahr 1977 ist zwar nicht mehr das aktuellste, aber lesenswert ist es allemal. Es erzählt zahlreiche Episoden aus der Geschichte der Kryptologie, ohne den Leser zu überfordern. Tobias Schrödel, der wohl weltweit führende Experte für Kryptologie-Bücher, bezeichnet dieses Werk als ein “sehr sehr schönes, was nicht nur an den vielen tollen, teils seltenen Abbildungen liegt”.
Eine in der Tat sehr seltene und obendrein äußerst interessante Abbildung findet sich auf Seite 125 des Buchs. Es handelt sich um eine verschlüsselte Nachtricht, die von einem Tresorknacker aus den zwanziger Jahren stammt (hier gibt es sie in größerer Auflösung):

Schafft es jemand, die Verschlüsselung zu knacken?
Leider ist dem besagten Buch nicht zu entnehmen, wer der “gefährliche Tresorknacker” war und unter welchen Umständen er das Kryptogramm anfertigte. Vielleicht hat ein Leser eine Idee. Immerhin ist eine Quelle angegeben: Peter Way hat die Tresorknacker-Nachricht einem Artikel aus den Illustrated London News (Ausgabe vom 25.8.1928) entnommen. Leider habe ich es bisher nicht geschafft, an diesen Artikel heranzukommen (es gibt zwar ein Online-Archiv, doch dieses ist für mich nicht zugänglich). Falls ein Leser weiterhelfen kann, würde ich mich sehr freuen.
Peter Way erwähnt im selben Kapitel außerdem den Mafia-Boss Frank Costello (1891-1973). Dieser soll 20 Jahre lang ein Verschlüsselungssystem verwendet haben, das ihn gegen die Postüberwachung durch das FBI schützte. Von dieser Geschichte habe ich noch nie etwas gehört. Vielleicht weiß ja auch hier ein Leser mehr dazu.
Follow @KlausSchmeh
Zum Weiterlesen: Codeknacker auf Verbrecherjagd, Folge 8: Die Skorpion-Briefe

Kommentare (24)