
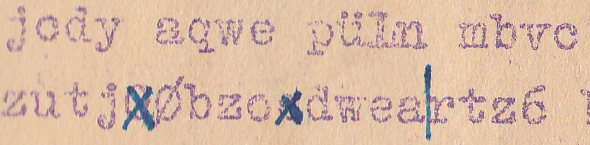
Wer klebte im Zweiten Weltkrieg verschlüsselte Zettel in ein Buch und welche Bedeutung haben diese Codes? Trotz zahlreicher Leserkommentare ist das Rätsel aus meinem Artikel vom letzten Freitag noch immer ungelöst. Heute kann ich ein paar zusätzliche Informationen dazu präsentieren.
Mein Blog-Artikel über das Rilke-Kryptogramm vom letzten Freitag war einer der meistgelesenen in Klausis Krypto Kolumne seit langem. Kein Wunder, schließlich geht es um eine spannende Geschichte: In ein Buch, das während des Zweiten Weltkriegs gedruckt wurde, hat ein Unbekannter mehrere Dutzend verschlüsselte Seiten eingeklebt. Ein handschriftlicher Vermerk der ersten Seite nennt einen Wachtmeister Klaus und ist auf April 1944 datiert.
Der Besitzer des Buchs ist Dr. Karsten Hansky. Er hat mir dankenswerterweise inzwischen alle beklebten Seiten des Buchs als Scan zur Verfügung gestellt. Hier gibt es eine Seite mit allen Scans in hoher Auflösung.
Hier sind ein paar zusätzliche Informationen:
- Auf einigen Seiten sind handschriftliche Korrekturen angebracht, beispielsweise auf Seite 5 (rechts im Bild).

- Auf den Seiten 4 und 5 sieht man außerdem, dass sich Farbe vom einem auf das andere Blatt übertragen hat.
- Der verschlüsselte Text ist vermutlich eine Hektografie. Das Hektografieren war vor Aufkommen des Fotokopierers eine weit verbreitete Möglichkeit, ein Schriftstück zu vervielfältigen. Leser über 40 kennen Hektografien sicherlich noch aus der Schule, wo diese Technik für Übungsblätter und Klassenarbeitsaufgaben angewendet wurde. Interessant ist: Hektografien waren die Methode der Wahl, wenn es um eine Auflage etwa zwischen 5 und einigen Hundert Exemplaren ging. Darunter war Blaupapier praktischer. Mehr als einigen Hundert Kopien machte die Vorlage (Matrize) nicht mit.
- Die Leser Narga und Mr X haben eine interessante Beobachtung gemacht: Viele Textpassagen (z. B. “cxsw”, “asdfghj” oder “wert”) bestehen aus Buchstaben, die auf der Tastatur nebeneinander liegen. Lässt sich dieser Verdacht erhärten?
- Die Null ist immer mit Schrägstrich dargestellt. Dies hat normalerweise den Zweck, dass man die Null vom Buchstaben O unterscheiden kann. In diesem Fall erscheint diese Maßnahme aber unnötig, da Kleinbuchstaben verwendet werden. Dabei ist am uneinheitlichen Aussehen der quergestrichenen Nullen klar, dass diese in drei Schritten (und damit recht umständlich) gedruckt wurden: 0 -> Wagenrücklauf -> /.
- Karsten Hansky hat sich neben dem Rilke-Buch mit eingeklebten Zettel auch ein normales Exemplar besorgt. Dadurch kann ich im Folgenden die Seiten 38 und 39 im Original und in der präparierten Version zeigen.


- Sowohl Karsten Hansky als auch der Leser Max Baertl haben festgestellt: Die auf der ersten Seite eingetragegene Zahl 06531 war die Feldpostnummer der FAK.624 (Fernaufklärungskompanie) und war als Teil der KONA 5 in Frankreich stationiert.
Nachdem nun alle Scans verfügbar sind, könnte man das Kryptogramm mit den üblichen Textstatistiken untersuchen. Vielleicht hat ja ein Leser Lust, dies zu tun. Die Resultate würden mich sehr interessieren. Gleiches gilt natürlich für alle anderen Anmerkungen und Ideen zu diesem spannenden Rätsel.
Follow @KlausSchmeh
Zum Weiterlesen: Eine versteckte Nachricht aus dem Zweiten Weltkrieg

Kommentare (38)