

Wir schreiben das Jahr 2021. Es ist peinlich über diese Dinge schreiben zu müssen: Dieser Blogbeitrag ersetzt keine Vorlesung. Er beschreibt nur wenige der wirklich wichtigen Aspekte wissenschaftlicher Software – und hat nicht einmal den Anspruch auf Vollständigkeit. Allerdings …. wie mein letzter Beitrag in dieser Reihe gezeigt hat, gibt es bei Veröffentlichungen in der Bioinformatik ein paar Auffälligkeiten:
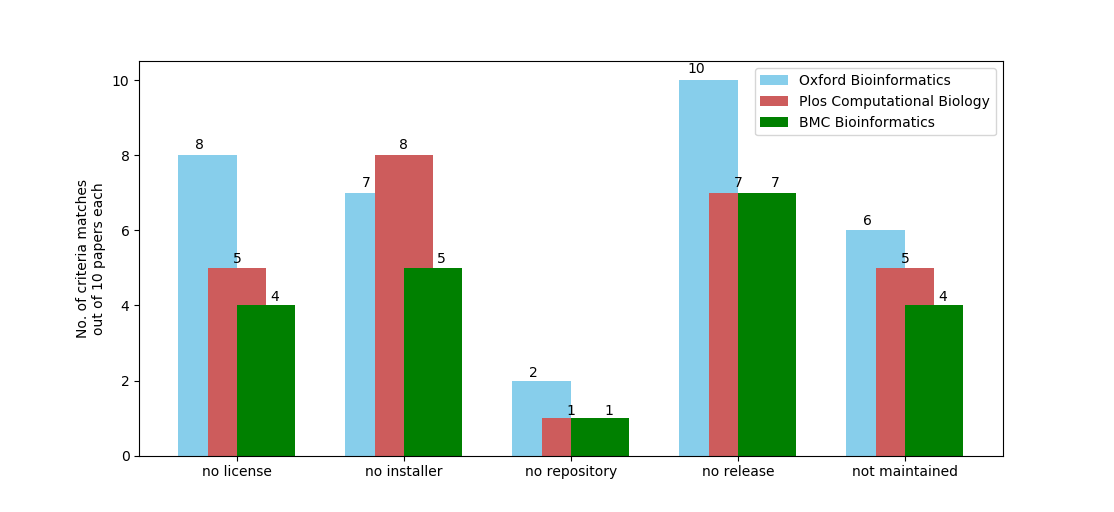
Mal fehlt die Lizenz, mal gibt es keine Installationsroutine, mal keinen versioniertes Bündel des Quellcodes. Oft auch ist Bioinformatiksoftware publish and forget: Auf einem miesen Stand eingefroren und unbenutzbar, nur dazu gedacht ein paper zu erzeugen. Und meine Erhebung vom letzten Mal ist die Crème de la Crème. Ein Artikel wie dieser hier wurde beispielsweise erst gar nicht in einem Bioinformatikjournal veröffentlicht und erwähnt “custom-made Python 2.7.6 scripts” die aber nirgends zu finden sind (ich hatte diese gesehen und impliziert kommentiert: sie sind mau), und ist somit per definitionem nicht reproduzierbar, da eine wissenschaftliche Analyse darauf beruht und niemand jemals diese Scripte anwenden kann, schon weil sie nirgendwo zu haben sind.
Und ab hier: Bitte konstruktiv!
Kritteln kann jeder. Manchmal ist das auch notwendig, um so ein wenig Bewusstsein für die Probleme zu wecken. Hier aber der Versuch konstruktiv zu sein als Appell an die BiologInnen und BioinformatikerInnen in der Leserschaft: Wenn ihr mal Software in der Bioinformatik (oder in einer anderen wissenschaftlichen Diziplin – Code aus der theoretischen Physik, beispielsweise, den ich bisher gesehen habe ist mit ähnlichen Problemen in noch stärkerem Umfang behaftet) veröffentlichen wollt, ein paar Tipps, damit nicht andere eure Publikation beim Journalclub zerpflücken, sie hier im Blog auftaucht oder – schlimmer noch – erst gar nicht weiter beachtet wird:
Lizenzen
Wie mein letzter Beitrag gezeigt hat, ist Software in der Bioinformatik häufig ohne Lizenz publiziert. Und das ist deshalb ein Problem, weil man diese Software eigentlich auf öffentlichen Systemen nicht nutzen kann. Ohne Lizenz gilt immer, dass die allgemeinen urheberrechtlichen Bestimmungen gelten, die Entwickler bzw. ihre Arbeitgeber die Rechte am Code halten und folglich Dritte das Projekt nicht forken können und daran weiterentwickeln. Vor Allem: Auf einem öffentlich-rechtlichen System (also alle durch Bund oder Länder finanzierten Systeme) dürfen die Administratoren eigentlich solche Software nicht installieren.
Wenn man sich das mal überlegt ist es ziemlich Panne als öffentlich bezahlte(r) WissenschaftlerIn Code für die Mülltonne zu schreiben, oder? Vor allem aber: Wer ein Programm / Workflow / Pipeline / Softwarebibliothek veröffentlicht, möchte doch, dass damit Ergebnisse erzielt werden. Und so manche Karriere hat sich schon aus einer Software ergeben. Wenn eine solche Software jedoch nicht anwendet werden darf, kann ein damit gewonnenes wissenschaftliches Ergebnis nicht reproduziert werden. Oder viel mehr: Darf es eigentlich nicht.
Die Diskussion dazu ist nicht neu, schon 2012 hat James Governor das Problem benannt:
younger devs today are about POSS – Post open source software. fuck the license and governance, just commit to github.
— Basic Maslow (@monkchips) September 17, 2012
Für die nicht einschlägig bewanderten LeserInnen: Wissenschaftliche Software ist etwas Spezielles. Apps für Smartphones und Tablet-Computer prägen unser Weltbild. Wissenschaftliche Software auch, vielleicht nicht so direkt und unmittelbar – sondern oftmals unscheinbar aber nachhaltig über die damit gewonnenen wissenschaftlichen Erkenntnisse. Und die öffentliche Hand zahlt (zumindest indirekt) für die Erschaffung dieser Software. Sie möchte auch, dass diese wieder den wissenschaftlichen Communities zugutekommt. Als Gesellschaft haben wir daran ebenso ein Interesse wie daran, dass wissenschaftliche Ergebnisse nicht hinter Paywalls verschlossen sind und dann für teures Geld wieder gekauft werden müssen. Auch deshalb ist die Lizenzfrage nicht ganz unwichtig.
Welche Lizenz darf es denn sein?
Zunächst einmal sollte wissenschaftliche Software quelloffen sein (open source). Für viele klingt das selbstverständlich, ist es aber nicht. Es gibt wissenschaftliche Software, die dürfte ich noch nicht mal mit anderen gleichförmigen Ansätzen vergleichen, geschweige denn in Code schauen, ob dieser einwandfreie Ergebnisse liefert. Oder die Programme sind vorgebaut (vor-kompiliert herunterzuladen) und man muss alles glauben, was diese errechnen. In der genomorientierten Bioinformatik ist solch ein Verhalten eher selten (wenigstens etwas Gutes), aber ich erinnere mich an die Präsentation eines Kompressionsformates für genetische Rohdaten, dass von einer Gruppe der Frauenhofergesellschaft entwickelt wurde. Eine sehr interessante Angelegenheit, versprachen sie doch parallel komprimieren und dekomprimieren zu können. Genetische Rohdaten können bei großen Studien schnell mal hunderte Terrabyte erreichen und Speicher ist teuer. Dumm nur, dass die Softwarebibliothek hierfür erst mal patentiert werden sollte, bevor man Näheres erfahren durfte. Seit nunmehr fast drei Jahren habe ich von dieser Entwicklung nichts mehr gehört …
Aber ihr wollt es ja besser machen, oder? Also eine freie Lizenz (nicht dasselbe wie Freeware)! Nun, hier im Blog gibt es keine definitive Empfehlung. Dieser Blogpost solle eine ganze Weile im Netz stehen und ab und an gibt es Änderungen in altbekannten Lizenzen oder gar neue Lizenzen. Doch ein paar Hinweise dürfen sein:
Also, zunächst gilt es vielleicht noch ein immer noch verbreitetes Missverständnis zu bekämpfen: Als Autoren gebt ihr euer Copyright, eure Urheberschaftsrechte nicht ab, wenn ihr Code unter eine Open-Source-Lizenz stellt. Ihr erteilt lediglich das Recht auf Nutzung und – gerade im Vergleich mit proprietärer Software weitreichende – weitere Rechte. So zum Beispiel den Code zu verändern und ggf. wieder zu eurem Projekt unter euren Bedingungen zurückzugeben. Und wie wählt man nun eine Lizenz aus?
Ein paar Hintergründe
Quellcode oder source code ist die menschenlesbare Form einer Programmiersprache. Open source meint eine Lizensierung, die fordert, dass der Quellcode allen NutzerInnen zugänglich ist und das diese in die Lage versetzt sein sollen den Code zu verwenden, zu modifizieren und weiterzugeben. Ohne Zugang zum Quellcode können WissenschaftlerInnen nicht nachvollziehen und verstehen (oder verändern) wie euer Programm (oder Softwarebibliothek) funktioniert. Die Zugänglichkeit von Quellcode kann KollegInnen helfen Bugs zu finden und vielleicht auch zu lösen, die andernfalls schwer aufzufindende Fehler bei der Analyse von Daten nach sich ziehen können. Vielleicht gelingt es euch auch Gleichgesinnte zu gewinnen, die gemeinsam mit euch weiterentwickeln wollen? So könnt auch ihr euch neuen Projekten zuwenden ohne eure hart erarbeitete Software auf dem Müllhaufen wissenschaftlicher Publikationen zu sehen.
“Zulassend” vs. copyleft
Zulassend (bzw. permissive) und copyleft sind Bezeichnungen aus der FOSS-Community (FOSS = Free Open Source Software) und sollen den Unterschied zu gewerblichen Lizenzen hervorheben. Zulassende Lizenzen sind jene mit den wenigsten Einschräkungen für den potentiallen Anwenderkreis. Meist fordern sie explizit, dass die Erschaffer der Software beim Weitergeben und Verändern von Software und Quellcode erwähnt bleiben. Diese zulassenden Lizenzen werden in der angelsächsischen Welt “academic style licenses” genannt, weil sie so häufig von wissenschaftlichen Institutionen genutzt für ihre Software genutzt werden[Bretthauer, 2001].
Beispiele für FOSS-Lizenzen sind die BSD-Lizenz (von Berkeley Software Distribution) und die MIT-Lizenz (ursprünglich vom Massachusetts Institute of Technology), die beide sehr ähnlich sind oder auch die Apache-Lizenz.
EntcklerInnen, die einen dauerhaften open source-Zugriff auf ihr Werk gewährleisten möchten, verwenden Lizenzen mit dem copyleft-Prinzip. Das Wort spielt natürlich auf “Copyright” an. Copyleft greift die das Copyright-Prinzip auf, um einen “ewigen” open source-Zugriff zu garantieren. Hier fordert die Lizenz, dass jede von der ursprünglichen Software abgeleitete Software ebenfalls unter derselben Lizenz wie das Original vertrieben wird. Daher wird das copyleft-Prinzip manchmal auch als besonders restriktiv wahrgenommen.
Beispiele für Lizenzen nach dem copyleft-Prinzip sind die GNU General Public License (GPL), die davon abgeleitete GNU Lesser General Public License (LGPL) oder die Mozilla Public License (MPL).
Nun, ein Blogger ist kein Rechtsanwalt, es gibt keine bestimmten Rat. Aus rein praktischen Gesichtspunkten rate ich eine kleine Liste wie diese abzuarbeiten:
- github hat eine Seite “Choose an open source license” gelauncht. Lest durch, was dort steht und trefft eine Vorauswahl.
- Lest euch die Lizenzen durch, die in die engere Wahl kommen.
- das Rechenzentrum eurer Institution kann ggf. weiterhelfen: die Leute dort sind keine Rechtsanwälte und habe keine eigene Rechtsabteilung, können aber in der Regel beurteilen, ob Eure Vorauswahl sinnvoll ist.
- ggf. hat eure Institution auch Vorgaben – bei der Frauenhofergesellschaft ist das beispielsweise so. In diesem Fall müsst ihr Euch natürlich daran halten.
- vergleicht eure Software mit anderen, vergleichbaren Werkzeugen
- wenn ihr ein kommerzielles Lizenzmodell wählen wollt, sucht euch definitiv eine Rechtsberatung!
Insgesamt braucht dieser Prozess kaum Zeit – also gibt es auch keine Entschuldigung dafür, dass es Veröffentlichungen ohne Lizenzen gibt. Spätestens wenn eure Software etwas taugt, werden mögliche NutzerInnen danach fragen – und dann ist es peinlich nachliefern zu müssen.
Euer Ziel ist es, dass die Software verwendet wird: Also verseht sie mit einer offenen Lizenz, ihr seid ja (noch) WissenschaftlerInnen, keine Unternehmensmitarbeiter!
Installationsroutinen
Viele Leute in der Bioinformatik arbeiten auf einem Server einer bestimmten Arbeitsgruppe. Da kann man die eigene Software und auch die von Dritten einfach irgendwo ablegen und laufen lassen. Ich vermute, dass ist auch der Hintergrund für das Häufige “Klont von github und lasst mein Script laufen.”, das man unter der Rubrik “Nutzung der Software” findet.
Dumm ist nur, dass diese Annahme nicht überall zutrifft. Auf Multinutzersystemen kann zwar jeder irgendwelche Skripte irgendwo im eigenen Heimverzeichnis ablegen. Aber auf zentral installierte Software trifft das meist nicht zu. Da gibt es Einschränkungen, denn die Software muss gut von allen Nutzern zu nutzen sein. Dabei ist die Erstellung von Installationsscripten nicht schwer: Python bietet die distutils, R bietet eine etwas sehr umfangreiche Anleitung zur Erstellung von Paketen – man sollte sich aber nicht abschrecken lassen, selten nur braucht man alles. Um für C/C++/Fortran Software zu bauen gibt es schon lange GNU make. Das finden viele, mich eingeschlossen, etwas umständlich. In der Vergangenheit hätte ich SCons empfohlen, mittlerweile eher CMake. Alle diese Werkzeuge verlangen Einarbeitung. Das ist aber bei Containern oder Paketmanagern auch so. Und einmal eingearbeitet ist die Erstellung weiterer Installationsscripte kein Hexenwerk mehr. Mehrwert für eure Nutzer: Sie können eure Software fast überall installieren. Mehrwert für euch: Potentielle Nutzer sind nicht gleich an diesem Punkt abgeschreckt.
Paketmanager und Container sind keine Installationsroutine
Paketmanagern habe ich gerade schon erwähnt: Mit Conda, oder beispielsweise Homebrew für die Apple-Nutzer, könnt ihr natürlich den Code leichter unter die Leute bringen. Aber wenn ich schon Brew erwähne: Das läuft zum Beispiel nicht für nicht-Apple-Nutzer. Eine Installationsroutine ist immer beschränkt für eine bestimmte technische Umgebung: Microsoft Installer (die Programme mit msi-Suffix, die bestimmt alle hier schon mal gesehen und genutzt haben) eben für Microsoft-Betriebsysteme und Makefiles häufig für Linux/Unix (auch wenn sie für Windows angepasst werden können). Aber mit Brew schränkt ihr den Kreis möglicher Nutzer unnötig ein. Ähnlich bei Conda. Nur wer Conda nutzen kann, kann auch euer Conda-Build nutzen. Das geht aber nicht überall (Clustersysteme verbieten häufig Conda aus Performancegründen).
Es spricht nichts dagegen Conda- oder Brew-Lösungen zusätzlich als Service an NutzerInnen anzubieten. Testern eurer Software können sie das Leben auch sehr vereinfachen. Aber bietet nicht ausschließlich Conda-Pakete oder Brew an, fragt euch mal lieber wo eure Software laufen soll? Nur auf Apple-System? Nur auf Windows-Rechnern?
Ach, und weil google das jetzt hip findet. Nein, Software nur noch als Container zu verteilen, ist auch keine Lösung. Da wird gerne mal alles zusammen gepfropft, was notwendig ist, um die fragliche Software im Container zum Laufen zu bekommen. Der Vorteil ist: NutzerInnen können schnell loslegen die Software zu nutzen. Aber ihr schränkt den Entwicklerkreis beträchtlich ein, weil der Entwicklungszyklus noch etwas komplizierter wird. (An dieser Stelle könnte ein Rant über Entwicklung mit Containern stehen, aber um die geht es hier ja nicht in erster Linie.) Und vor allem setzt ihr voraus, dass alle euren Containertyp nutzen oder zumindest konvertieren können.
Nutzt Quellcodemanagement- / Versionsverwaltungssysteme
Immer noch, wir schreiben das Jahr 2021, ist die Nutzung von Quellcodemanagementsystemen (SCM, source code mangagement) nicht selbstverständlich. Dabei dürfte es kaum eine Universität geben, die keine Einstiegskurse zu git oder anderen Systemen anbietet. Nur so könnt ihr aber alle Veränderungen nachvollziehen, die ihr in euren Code einbringt.
Ihr braucht so einen Kram nicht? Ist ja nur ein kleines Stück Software, dass ihr schreibt und sowieso: Die paar kleinen Fehler, sind schnell ausgebügelt!? – Schön für euch, die meisten Programmierer schreiben keine fehlerfreie Software (dieser Beitrag richtet sich ja an LeserInnen, die nie Softwareengineering gehört haben, also die Untersuchungen hierzu nicht kennen) und können auch keine Seiteneffekte von Veränderungen vorhersehen. Ein SCM zu verwenden macht euren Code nicht besser, aber es die Grundbedingung ein(e) weniger schlechte(r) ProgrammiererIn zu sein.
Softwarereleases
Wenn ihr ein solches Quellcodemanagementsystem nutzt, protokolliert es nicht nur alle eure Veränderungen mit. Es erlaubt euch auch einen “Release” zu bündeln und eine Versionsnummer daran zu heften. Nee, einfach nur ein Quellcodebündel hochladen und vergessen ist weder git nutzen, noch die Software anwendbarer machen. Ist noch nicht mal freundlich gegenüber den Kolleginnen und Kollegen, die echtes Interesse zeigen.
Kommandozeilenprogramme
Die meiste wissenschaftliche Software funktioniert nur auf der Kommandozeile. Und das aus gutem Grund: So ist eine Applikation schneller zu entwickeln (als wenn man eine Webseite drum herum designen muss oder eine graphische Benutzeroberfläche). Obendrein lassen sich Kommandozeilenprogramme gut in Reihe schalten und so verschiedenartige Aufgaben der Datenverarbeitung nacheinander ausführen – nötigenfalls auch über ein Workflowsystem mit graphischer Benutzeroberfläche.
Einige der in Augenschein genommenen Skripte und Programme erwarten ihre Argumente in einer bestimmten Reihenfolge, weil sie ausschließlich im Eigenbau die Eingaben verarbeiten. Das kann sich jedoch kein Schwein merken. Um solch ein Interface zu programmieren bietet jede gebräuchliche Programmiersprache Bibliotheken auf. Nutzt die Dinger, erfindet nicht das Rad neu!
Software sollte EINE NUTZBARE Lösung sein
Wenn ihr eine Software schreibt, sollte sie eine Lösung für ein Problem sein. Der Versuch eierlegende Wollmilchsäue zu programmieren ist nahezu immer zum Scheitern verurteilt und gerade Anfänger erliegen schnell der Versuchen für ihre Chefs Wunderwerke erstellen zu wollen. Es schadet nicht Beispiele zur Ausführung auf bestimmten Systemen, z. B. dem System auf dem ihr entwickelt habt beizufügen. Aber wenn das nur das eine System ist, dass für eure Gruppe gehostet wird und man euch sonst die Ohren wegen eurer In-Effizienz abreissen würdet, wenn ihr dieses System verlasst …. hm, dann sollte das vielleicht eher nicht etwas sein von dem mögliche Nutzer abhängen. Und ja, eure Software ist zu spezifisch, wenn wie im verlinkten Beispiel, alle eure Dateien (hardcoded) im Script, im Code stehen: Dritte können so eure Software nur nutzen, wenn sie diese editieren oder neu schreiben.
Fazit
Wenn ihr die beschriebenen Fehler (vor allem die letzten paar) macht, seid ihr nahezu sicher, dass eure Software dazu beitragen wird so richtig viel Salz in den großen Topf der Reproduzierbarkeitskrise zu schütten. So etwas will niemand auslöffeln. Eure Software anwendbar zu machen wird die Strafarbeit für mögliche Nachfolger.
![]()

Kommentare (5)