
Vor sieben Jahren veröffentlichte der Bundesnachrichtendienst vier verschlüsselte Nachrichten. Drei davon sind bis heute ungelöst.
English version (translated with DeepL)
Vor sieben Jahren berichtete ich zum ersten Mal über eine Reihe von Kryptologie-Webseiten des Bundesnachrichtendiensts (BND). Jörg Drobick, damals wie heute ein Leser dieses Blogs, hatte mich darauf aufmerksam gemacht. Leider sind diese durchaus interessanten Seiten inzwischen aus dem BND-Webauftritt verschwunden. Dies gilt auch für vier kryptologische Rätsel, die der BND dort unter dem nicht gerade reißerischen Titel “Kryptologie – Beispieltexte” veröffentlicht hatte.
Quelle/Source: BND
Hier sind die vier “Beispieltexte” (es handelt sich um Screenshots der Original-Seite des BND):

Quelle/Source: BND

Quelle/Source: BND
Die Klartexte zu den ersten drei Rätseln sind laut BND in deutscher Sprache abgefasst, der vierte in (amerikanischem) Englisch.
Nach meinem Artikel von 2014 veröffentlichten meine Leser insgesamt 45 Kommentare, doch keines der vier Rätsel wurde gelöst.
Ein zweiter Versuch
2017 berichtete ich ein zweites Mal über die vier BND-Krypto-Rätsel. Dieses Mal legte ich den Schwerpunkt auf dem ersten “Beispieltext”:
UELNW ETTHE CSTEN AGSEZ UCPRL INEIE DISSS CINRA DUAZN AETTC ÜITWE ADLTG CRSNH FTULD HNIHL EATMA ZNRHS ÜEBUV TSEAN
Die folgende Häufigkeitsanalyse (erstellt mit CrypTool 2) zeigt, dass die Buchstaben-Häufigkeiten denen der deutschen Sprache entsprechen:
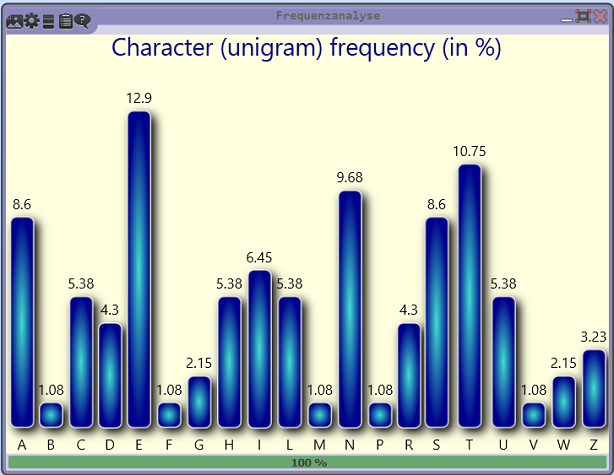
Quelle/Source: CrypTool
Dies spricht stark für eine Transpositions-Chiffre. Blog-Leser Ralf Bülow war der erste, der den Klartext ermittelte. Ihm war aufgefallen, dass das Kryptogramm die gleichen Buchstaben enthielt wie die ersten zwei Sätze des Grundgesetzes:
Die Würde des Menschen ist unantastbar. Sie zu achten und zu schützen ist Verpflichtung aller staatlichen Gewalt.
Blog-Leser Marc fand heraus, dass es sich tatsächlich um eine Transpositions-Chiffre handelte, und zwar um das Doppelwürfel-Verfahren. Die beiden Schlüsselwörter lauten VERFASSUNG und GRUNDGESETZ. Damit war das erste BND-Rätsel gelöst.
Ein dritter Versuch
Vor einer Woche erhielt ich eine Nachricht von einem Blog-Leser aus Nürnberg, der fragte, wie es den mit den BND-Challenges stand. Meine Antwort war einfach: Meines Wissens gab es seit Jahren nichts Neues. Die “Beispieltexte” sind also zu einem kryptologischen Cold Case geworden. Auf der BND-Webseite sind sie nicht mehr zu finden.
Doch Cipherbrain hat bekanntlich ein gutes Gedächtnis. Deshalb möchte ich die drei ungelösten “Beispieltexte” heute noch einmal vorstellen. Hier sind sie:
Text 2:
D8 B9 42 86 0B 6C E6 C5 8F 63 41 46 53 B7 99 8F A8 C8 65 94 F5 98 09 BE B4 63 B1 C3 34 54 09 73 BD C4 AE E4 BF 01 0E 34 F2 A9 0A CF 16 71 A5 DE 98 2B 58 47 1D F6 94 8F A1 DE 2B DD B0 C3 23 B8 B2 2F E6 FA 27 5C 09 73 E5 8D A1 AF
Text 3:
4D 8F 3B 0E 02 31 0C 44 AF E2 03 F0 39 C3 AE A0 A0 A0 40 9C 20 9B 0C 1B 8B C8 42 8E 43 C1 79 39 C6 16 38 A9 A8 2C 7B 9E 67 EC 33 0B 4D AD 96 20 A9 4A 88 59 39 66 83 24 86 54 DB 51 82 52 6A 1A 33 F9 84 32 34 B4 AA 61 75 00 74 6B A1 B0 7D 8D 2A 58 9C 9B 74 01 1B 35 49 03 BE 88 61 D5 7F E0 CA 16 06 03 3D EE 59 04 42 5D 10 5F 79 43 3F 3D 79 09 EA FD EC 8C A7 D0 63 D3 61 75 77 09 9A BB 7B 3F 68 F6 08 54 C5 AB 2D 85 9F 74 42 B3 1A 73 7F 61 84 73 D6 0E 6D BA 7A 29 E0 6A B0 C3 0F
Text 4:
4A 16 17 9B 71 B1 96 6E 5A 55 A2 34 FF C7 46 02 CC 69 3E C1 B6 55 DE 1E A8 47 51 C4 BA 82 3F E0 FE C6 29 7F 74 F7 28 86 97 60 85 75 18 50 F5 B6 60 B9 AF 3A B6 EE 30 D5
Wie man sieht, handelt es sich in allen drei Fällen um Hexadezimalzahlen. Möglicherweise lassen diese sich in Buchstaben oder andere Zeichen umwandeln. Wer eine Idee zur Entschlüsselung dieser drei Kryptogramme hat, möge sich melden. Vielleicht lässt sich dieser Cold Case nach all den Jahren lösen.
Follow @KlausSchmeh
Further reading: Christoph’s Chaotic Caesar Challenge
Linkedin: https://www.linkedin.com/groups/13501820
Facebook: https://www.facebook.com/groups/763282653806483/

Kommentare (16)